FINEOntoLogX: انقلاب در تحلیل لاگهای امنیت سایبری با گرافهای دانش و مدلهای زبانی بزرگ
در دنیای امروز، تهدیدهای سایبری هر روز پیچیدهتر، سریعتر و غیرقابلپیشبینیتر میشوند. سازمانها، دولتها و حتی کاربران عادی، در معرض حملاتی قرار دارند که با استفاده از هوش مصنوعی، یادگیری ماشین و روشهای پنهانسازی پیچیده طراحی میشوند. یکی از مهمترین منابع برای درک و تحلیل این تهدیدها، لاگهای سیستم هستند؛ دادههایی که در ظاهر سادهاند، اما درون خود ردپای مهاجمان، آسیبپذیریهای exploited شده و مسیرهای نفوذ را پنهان دارند. اما این لاگها معمولاً بیساختار، حجیم و ناهمگون هستند. پروژهای به نام FINEOntoLogX، که توسط پژوهشگران دانشگاههای برشا، تورین، کاردیف و ساوتهمپتون توسعه یافته، پاسخی نوآورانه برای این چالش ارائه میدهد.
مقدمه: چالشی به نام لاگهای امنیتی
در دنیای امروز، تهدیدهای سایبری هر روز پیچیدهتر، سریعتر و غیرقابلپیشبینیتر میشوند. سازمانها، دولتها و حتی کاربران عادی، در معرض حملاتی قرار دارند که با استفاده از هوش مصنوعی، یادگیری ماشین و روشهای پنهانسازی پیچیده طراحی میشوند. یکی از مهمترین منابع برای درک و تحلیل این تهدیدها، لاگهای سیستم هستند؛ دادههایی که در ظاهر سادهاند، اما درون خود ردپای مهاجمان، آسیبپذیریهای exploited شده و مسیرهای نفوذ را پنهان دارند. اما این لاگها معمولاً بیساختار، حجیم و ناهمگون هستند. در نتیجه، استخراج اطلاعات مفید از میان میلیونها خط لاگ، به یکی از بزرگترین چالشهای امنیت سایبری تبدیل شده است. پروژهای به نام FINEOntoLogX، که توسط پژوهشگران دانشگاههای برشا، تورین، کاردیف و ساوتهمپتون توسعه یافته، پاسخی نوآورانه برای این چالش ارائه میدهد و با استفاده از فناوریهای پیشرفته، راهحلی برای مدیریت این حجم عظیم داده ارائه میکند.
FINEOntoLogX چیست؟
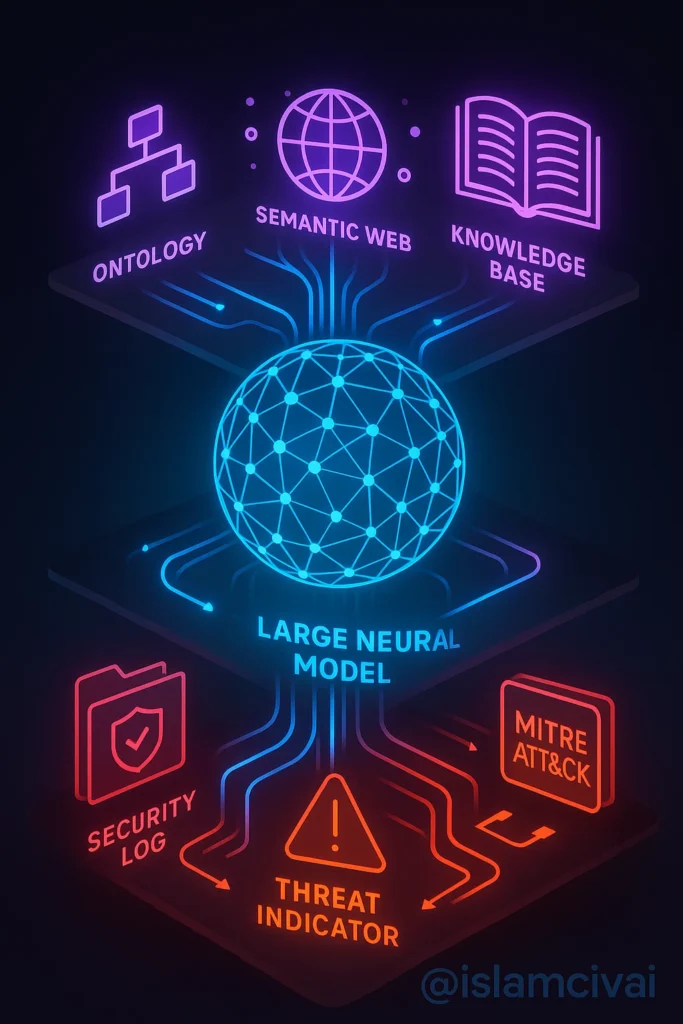
FINEOntoLogX یک سامانه هوش مصنوعی خودکار است که با تکیه بر مدلهای زبانی بزرگ (LLMs)، دادههای خام لاگ را به گرافهای دانش مبتنی بر آنتولوژی تبدیل میکند. این گرافها در واقع نقشهای معنایی از وقایع امنیتی هستند که ارتباط میان رویدادها، کاربران، دستگاهها، و رفتارهای مهاجم را به شکل قابل درک و تجزیهپذیر نمایش میدهند. به زبان ساده، OntoLogX لاگهای پراکنده را به داستانی منسجم از حمله سایبری تبدیل میکند — از اولین تماس مهاجم تا شناسایی تاکتیکها بر اساس چارچوب MITRE ATT&CK. این سیستم با قابلیت خودکارسازی، امکان تحلیل سریعتر و دقیقتر را برای تیمهای امنیتی فراهم میکند.
چرا آنتولوژی اهمیت دارد؟
آنتولوژی در علوم داده به معنی «مدل مفهومی از دانش» است. در این پروژه، از یک آنتولوژی سبک امنیتی برای تعریف مفاهیم کلیدی مثل “event”، “IP”، “threat actor” و “session” استفاده شده است. این آنتولوژی پایهای محکم برای تبدیل دادههای غیرساختاری به دادههای قابل استنتاج و اشتراکپذیر فراهم میکند. بدون وجود آنتولوژی، مدل ممکن است فقط به بازنویسی دادهها بپردازد. اما با آنتولوژی، دادهها معنا پیدا میکنند و سیستم قادر است بفهمد که مثلاً یک آدرس IP مربوط به مهاجم است، یا رویداد خاصی بخشی از یک حمله بزرگتر است. این ویژگی بهویژه در شناسایی الگوهای پیچیده امنیتی بسیار مفید است.
نقش مدلهای زبانی بزرگ (LLMs) در OntoLogX
مدلهای زبانی بزرگ مانند GPT یا CodeLlama توانایی فوقالعادهای در درک زبان طبیعی دارند. OntoLogX از این قدرت برای تبدیل جملات متنی لاگها به ساختارهای معنایی دقیق استفاده میکند. به طور خاص، در فرآیند OntoLogX سه مرحلهی کلیدی وجود دارد:
-
-
- بازیابی دانش (Retrieval-Augmented Generation یا RAG): در این مرحله، مدل برای هر لاگ، اطلاعات مرتبط از آنتولوژی را بازیابی میکند تا درک دقیقتری از مفاهیم بهکاررفته داشته باشد.
- تولید گراف اولیه: LLM بر اساس داده و آنتولوژی، گراف اولیه را میسازد که شامل نودها و روابط است.
- اصلاح و ارزیابی تکراری (Iterative Correction): مدل در چند مرحله خروجی را تصحیح میکند تا گراف نهایی از نظر نحوی و معنایی معتبر باشد.
از لاگ تا گراف دانش: فرآیند گامبهگام
گام ۱: استخراج رویدادهای اولیه
سیستم ابتدا لاگها را با تکنیکهای پیشرفته پردازش زبان طبیعی (NLP) تجزیه کرده و موجودیتهای کلیدی مانند آدرس IP، نام کاربری (یوزر)، زمان وقوع، و نوع عملیات را شناسایی میکند. این مرحله با بهرهگیری از الگوریتمهای پیچیدهای مانند تحلیل نحوی (Syntax Parsing) و تشخیص موجودیتهای نامدار (Named Entity Recognition) انجام میشود تا دقت استخراج به حداکثر برسد. علاوه بر این، سیستم از مدلهای یادگیری عمیق برای تشخیص الگوهای پنهان در متنهای لاگ استفاده میکند، که بهویژه در لاگهای پیچیده یا دارای نویز بسیار مؤثر است. برای بهبود عملکرد، دادههای اولیه با فیلترهایی برای حذف نویزهای غیرمرتبط (مانند لاگهای تکراری یا بیمعنی) پردازش میشوند، و این امر امکان تمرکز بر اطلاعات حیاتی را فراهم میکند. همچنین، این مرحله میتواند با دادههای تاریخی مقایسه شود تا زمینهای برای شناسایی انحرافات احتمالی از رفتار عادی سیستم ایجاد کند.
گام ۲: نگاشت مفهومی به آنتولوژی
هر موجودیت استخراجشده در گام قبلی به یک کلاس یا رابطه مشخص در آنتولوژی نگاشت میشود؛ بهعنوان مثال، رویداد “login_failed” به مفهوم “Authentication Failure” و یا “IP_address” به “Source_IP” در چارچوب آنتولوژی تبدیل میگردد. این نگاشت با استفاده از قوانین از پیش تعریفشده در آنتولوژی و الگوریتمهای تطبیق معنایی (Semantic Matching) انجام میشود، که تضمین میکند ارتباط بین دادهها و مفاهیم انتزاعی حفظ شود. برای افزایش دقت، سیستم از یک لایه اعتبارسنجی استفاده میکند که نگاشتها را با توجه به زمینه (Context) لاگ بررسی میکند؛ مثلاً اگر یک IP مکرراً در لاگهای مشکوک ظاهر شود، بهعنوان “Threat_Source” دستهبندی میشود. این فرآیند همچنین شامل یک مکانیزم بازخورد است که با تحلیل نگاشتهای نادرست، آنتولوژی را بهتدریج بهبود میدهد و انعطافپذیری سیستم را در برابر لاگهای جدید افزایش میدهد.
گام ۳: ساخت گراف دانش
نودها (مانند کاربران، دستگاهها، و رویدادها) و ارتباطها (مانند تعاملات یا توالیها) بر اساس ساختار تعریفشده در آنتولوژی ساخته میشوند تا تصویری جامع از حمله یا فعالیت سیستم ایجاد شود. این گرافها با استفاده از الگوریتمهای گرافسازی بهینه مانند PageRank یا Community Detection بهینه میشوند تا روابط مهمتر برجسته شوند و نویزها کاهش یابند. علاوه بر این، سیستم از تکنیکهای تجسم گراف (Graph Visualization) برای شناسایی الگوهای بصری استفاده میکند، که به تحلیلگران اجازه میدهد تا ارتباطات غیرمعمول را بهراحتی تشخیص دهند. این مرحله همچنین شامل یک فرآیند وزندهی پویا است که بر اساس فرکانس و اهمیت رویدادها، گراف را متعادل میکند، و امکان گسترش گراف با دادههای جدید را فراهم میکند تا تصویر کاملتری از سناریوی امنیتی ارائه دهد.
گام ۴: تحلیل سطح بالا با MITRE ATT&CK
در نهایت، مدل زبانی بزرگ (LLM) با تحلیل گراف تولیدشده، تاکتیکها و تکنیکهای مهاجم را با چارچوب MITRE ATT&CK تطبیق میدهد؛ بهعنوان مثال، تشخیص میدهد که فعالیت ثبتشده نشانهای از “Credential Access”، “Privilege Escalation” یا حتی “Lateral Movement” است. این تحلیل با استفاده از یک پایگاه داده بهروز از تاکتیکهای ATT&CK انجام میشود و گزارشهای دقیقی شامل جزئیات زمانی، بازیگران درگیر، و نقاط ضعف احتمالی سیستم تولید میکند. برای افزایش دقت، سیستم از یک لایه تأیید انسانی یا خودکار استفاده میکند که نتایج را با سناریوهای واقعی مقایسه میکند و پیشنهادات مداخلهای (مانند مسدود کردن IP یا بهروزرسانی فایروال) ارائه میدهد. این گزارشها همچنین میتوانند با سیستمهای مدیریت رویداد و اطلاعات امنیتی (SIEM) ادغام شوند تا پاسخدهی بلادرنگ به تهدیدات را تسهیل کنند.
مزایای OntoLogX در برابر روشهای سنتی
۱. خودکارسازی کامل تحلیل لاگها
در روشهای سنتی، تحلیلگر انسانی باید الگوها را بهصورت دستی جستوجو کند، فرآیندی که زمانبر، مستعد خطا، و وابسته به تجربه فرد است. در مقابل، OntoLogX از مدلهای زبانی بزرگ (LLMs) بهره میبرد که بهصورت خودکار ساختار حمله را از لاگها استخراج میکنند و این فرآیند را بهطور قابلتوجهی تسریع میکنند. این خودکارسازی نهتنها زمان تحلیل را کاهش میدهد، بلکه امکان پردازش حجم عظیمی از دادهها را در زمان واقعی فراهم میکند، که برای پاسخگویی سریع به تهدیدات سایبری ضروری است. همچنین، سیستم میتواند بهصورت 24/7 عمل کند، برخلاف محدودیتهای انسانی، و با یادگیری مداوم، دقت خود را در طول زمان بهبود بخشد.
۲. دقت بالا با استفاده از RAG
افزودن مرحلهی بازیابی دانش (Retrieval-Augmented Generation یا RAG) به OntoLogX باعث میشود مدل خطاهای تفسیری را بهطور قابلتوجهی کاهش دهد و اطلاعات دقیقتری ارائه کند، بهویژه در لاگهای پیچیده که ممکن است حاوی اصطلاحات فنی یا زمینههای متناقض باشند. این روش با دسترسی به یک پایگاه دانش خارجی، زمینههای مرتبط را به مدل تزریق میکند و از حدسزنی بیمورد جلوگیری میکند. بهعنوان مثال، در لاگهایی با دادههای ناقص، RAG میتواند با استناد به الگوهای قبلی، اطلاعات گمشده را استنتاج کند، که این امر دقت را در سناریوهای واقعی افزایش میدهد. همچنین، این تکنیک انعطافپذیری سیستم را در برابر تغییرات زبانی یا ساختاری لاگها حفظ میکند.
۳. اصلاح هوشمند خروجی
در بسیاری از سیستمهای مبتنی بر هوش مصنوعی، خروجی مدل نیاز به بازبینی دستی یا اضافی دارد، که این امر فرآیند را کند و پرهزینه میکند. اما OntoLogX با استفاده از یک مکانیزم اصلاح تکراری، خروجی نهایی را دقیق و معتبر میسازد و خطاها را به حداقل میرساند. این فرآیند شامل چندین دور بررسی خودکار است که با مقایسه نتایج با قوانین آنتولوژی و دادههای مرجع، ناسازگاریها را شناسایی و رفع میکند. بهعنوان مثال، اگر یک گراف دانش ناقص تولید شود، سیستم بهطور خودکار نودهای گمشده را پیشبینی و اضافه میکند. این قابلیت نهتنها دقت را افزایش میدهد، بلکه امکان استفاده از سیستم در محیطهای حساس مانند زیرساختهای حیاتی را تسهیل میکند.
۴. سازگاری با چند پایگاه گراف مختلف
در آزمایشهای انجامشده، گرافهای خروجی OntoLogX با چندین بکاند مختلف مانند Neo4j، RDF store، و حتی سیستمهای مبتنی بر گراف ابری تست شدند و سازگاری کامل داشتند، که انعطافپذیری بالای سیستم را نشان میدهد. این ویژگی به سازمانها اجازه میدهد تا OntoLogX را با زیرساختهای موجود خود ادغام کنند، بدون نیاز به بازطراحی کامل سیستمهای ذخیرهسازی. علاوه بر این، سازگاری با بکاندهای متنوع امکان مقیاسپذیری را فراهم میکند، بهطوری که سیستم میتواند از دیتابیسهای کوچک محلی تا پایگاههای داده عظیم ابری را پشتیبانی کند. این انعطافپذیری همچنین بهروزرسانیهای آینده و ادغام با فناوریهای نوظهور را سادهتر میکند.
دادههای مورد استفاده: از بنچمارک تا Honeypot واقعی
پژوهشگران OntoLogX را روی دو مجموعه داده آزمایش کردند:
- دادههای عمومی بنچمارک: شامل لاگهای استاندارد برای ارزیابی مدلهای امنیتی؛ محیطی کنترلشده برای مقایسهی عملکرد.
- دادههای Honeypot واقعی: مجموعهای از لاگهای واقعی از سیستمهای فریب (Honeypot) که مخصوصاً برای جذب مهاجمان ایجاد شدهاند. این دادهها بسیار چالشبرانگیزتر هستند، زیرا شامل رفتارهای واقعی، پیچیده و گاه غیرمنتظره مهاجماناند.
نتیجهها نشان دادند که OntoLogX در هر دو محیط عملکردی پایدار، دقیق و انعطافپذیر دارد و میتواند با انواع مختلف دادهها سازگار شود.
تحلیل نتایج: دقت و بازخوانی (Precision و Recall)
در ارزیابی کمی، پژوهشگران دقت و بازخوانی OntoLogX را در تبدیل لاگها به گرافهای دانش سنجیدند. نتایج حاکی از آن بود که:
- استفاده از RAG موجب افزایش حدود ۱۵٪ در Precision و ۱۲٪ در Recall شد.
- مدلهای Code-oriented (مانند CodeLlama) عملکرد بهتری نسبت به مدلهای عمومیتر مانند GPT داشتند.
- مرحلهی اصلاح تکراری موجب کاهش ۲۵٪ خطاهای معنایی در گرافهای نهایی شد.
ارتباط OntoLogX با MITRE ATT&CK
چارچوب MITRE ATT&CK به عنوان مرجع بینالمللی برای تحلیل تاکتیکها و تکنیکهای مهاجمان سایبری شناخته میشود. OntoLogX از این چارچوب برای تطبیق خودکار شواهد سطح پایین لاگها با اهداف سطح بالای حمله استفاده میکند. به طور مثال:
- تلاشهای ورود مکرر با رمز اشتباه → Credential Access
- ایجاد فایل موقت در مسیر سیستم → Persistence
- تغییر تنظیمات رجیستری → Defense Evasion
این تحلیل خودکار، به تیمهای امنیتی کمک میکند تا بدون صرف زمان طولانی برای بررسی دستی، مسیر حمله را شناسایی کنند.
ساختار فنی OntoLogX
۱. هسته هوش مصنوعی
در قلب سیستم، یک مدل زبانی بزرگ (LLM) قرار دارد که با دادههای امنیت سایبری بهطور خاص تنظیم دقیق (fine-tuned) شده است و برای تحلیل لاگها بهینه شده است. این مدل از معماریهای پیشرفته مانند ترنسفورمرها استفاده میکند که با مجموعهای عظیم از لاگهای واقعی و سناریوهای حمله آموزش دیدهاند تا الگوهای پیچیده را تشخیص دهند. تنظیم دقیق این مدل شامل استفاده از دادههای متنوع از هانیپاتها، لاگهای عملیاتی، و گزارشهای امنیتی است، که توانایی آن را در درک زمینههای مختلف افزایش میدهد. همچنین، هسته هوش مصنوعی با مکانیزمهای بهروزرسانی پویا مجهز شده تا با تهدیدات جدید و تکاملیافته همگام شود، که این امر آن را به یک ابزار تطبیقی برای محیطهای پویای سایبری تبدیل میکند.
۲. ماژول بازیابی (RAG)
این بخش بهعنوان «حافظه خارجی» عمل میکند و هنگام تولید گرافهای دانش، دادههای مرتبط از آنتولوژی و اسناد مرجع را به مدل تزریق میکند تا دقت و عمق تحلیل افزایش یابد. ماژول RAG از یک ایندکس جستوجوی پیشرفته استفاده میکند که شامل اصطلاحات امنیتی، تعاریف آنتولوژی، و اسناد تاریخی است، و این دادهها را در زمان واقعی بازیابی میکند. بهعنوان مثال، اگر لاگی حاوی یک IP ناشناخته باشد، RAG میتواند با جستوجو در پایگاه داده تهدیدات، زمینه مرتبط را ارائه دهد. این مکانیزم همچنین امکان سفارشیسازی را برای سازمانها فراهم میکند تا اطلاعات اختصاصی خود را به حافظه خارجی اضافه کنند، که انعطافپذیری سیستم را در محیطهای مختلف افزایش میدهد.
۳. ماژول اصلاح و تأیید
هر گراف تولیدی با استفاده از قوانین تعریفشده در آنتولوژی بررسی میشود و در صورت نیاز اصلاح میگردد تا انسجام منطقی حفظ شود و خطاها به حداقل برسند. این ماژول از یک فرآیند چندمرحلهای استفاده میکند که شامل اعتبارسنجی نحوی، بررسی معنایی، و تطبیق با الگوهای شناختهشده است. بهعنوان مثال، اگر یک رابطه بین دو نود بهطور نادرست تعریف شود، سیستم با مراجعه به آنتولوژی، آن را تصحیح میکند و پیشنهادهایی برای بهبود ارائه میدهد. این مرحله همچنین شامل یک سیستم بازخورد است که خطاهای تکراری را شناسایی کرده و آنتولوژی را بهصورت خودکار بهروزرسانی میکند، که باعث میشود سیستم با گذشت زمان دقیقتر و کارآمدتر شود.
۴. لایه ذخیرهسازی و مصورسازی
در نهایت، گرافهای دانش در پایگاههای دانش مانند Neo4j، GraphDB، یا حتی سیستمهای ابری مانند Amazon Neptune ذخیره میشوند و از طریق داشبوردهای تحلیلی قابل مشاهده هستند، که امکان تحلیل بصری را فراهم میکند. این لایه از ابزارهای تجسم پیشرفته مانند D3.js یا Cytoscape استفاده میکند تا گرافها را بهصورت تعاملی نمایش دهد، که به تحلیلگران اجازه میدهد روابط پیچیده را کاوش کنند. علاوه بر این، سیستم قابلیت خروجیگیری در فرمتهای مختلف (مانند JSON یا CSV) را دارد تا با سایر ابزارهای امنیتی ادغام شود. این لایه همچنین شامل یک مکانیزم فشردهسازی است که حجم دادهها را کاهش میدهد، که برای مدیریت پایگاههای داده بزرگ و بهینهسازی عملکرد در مقیاس بالا ضروری است.
مزایای کاربردی برای سازمانها
تحلیل سریعتر و دقیقتر حوادث امنیتی
OntoLogX با استفاده از مدلهای زبانی بزرگ و گرافهای دانش، امکان تحلیل سریعتر و دقیقتر حوادث امنیتی را فراهم میکند، بهطوری که سازمانها میتوانند در زمان واقعی تهدیدات را شناسایی و ارزیابی کنند. این سیستم با پردازش خودکار لاگها، زمان پاسخگویی را از ساعتها به دقیقهها کاهش میدهد و با ارائه تحلیلهای عمیق، از خطاهای انسانی جلوگیری میکند. بهعنوان مثال، در یک حمله Distributed Denial of Service (DDoS)، OntoLogX میتواند الگوهای ترافیک مشکوک را فوراً تشخیص دهد و پیشنهادات دفاعی ارائه دهد.
کاهش نیاز به تحلیلگران انسانی در مراحل اولیه
با خودکارسازی مراحل اولیه تحلیل، OntoLogX نیاز به دخالت گسترده تحلیلگران انسانی را کاهش میدهد، که این امر باعث صرفهجویی در هزینهها و منابع انسانی میشود. این سیستم میتواند بهصورت خودکار الگوهای اولیه را شناسایی کند و فقط موارد پیچیده یا نیازمند قضاوت انسانی را به تیمها ارجاع دهد. این ویژگی بهویژه در سازمانهای با تیم امنیتی کوچک یا تحت فشار بسیار مفید است و اجازه میدهد تحلیلگران بر استراتژیهای بلندمدت تمرکز کنند.
تولید خودکار گزارشهای قابلاستناد برای تیمهای SOC
OntoLogX گزارشهای خودکاری تولید میکند که برای تیمهای عملیات امنیتی (SOC) قابلاستناد و آماده ارائه به مدیران یا مراجع قانونی است. این گزارشها شامل جزئیات زمانی، شواهد گرافیکی، و تحلیلهای مبتنی بر MITRE ATT&CK هستند، که فرآیند مستندسازی را سادهتر میکند. همچنین، قابلیت سفارشیسازی این گزارشها برای نیازهای خاص سازمانی، مانند فرمتهای استاندارد صنعت، به بهبود ارتباطات داخلی و خارجی کمک میکند.
افزایش توانایی کشف حملات زنجیرهای (Multi-Stage Attacks)
این سیستم با تجمیع گرافهای دانش و تحلیل ارتباطات بین رویدادها، توانایی کشف حملات زنجیرهای را افزایش میدهد، که اغلب شامل چندین مرحله مانند نفوذ اولیه، جاسوسی، و گسترش است. OntoLogX میتواند توالی رویدادها را ردیابی کند و نقاط ضعف زنجیرهای را شناسایی کند، که به سازمانها کمک میکند تا قبل از تکمیل حمله، مداخله کنند. این قابلیت بهویژه در برابر حملات پیشرفته و مداوم (APT) بسیار مؤثر است.
امکان اتصال به SIEMها و سیستمهای CTI موجود
OntoLogX با امکان اتصال به سیستمهای مدیریت رویداد و اطلاعات امنیتی (SIEM) و پلتفرمهای هوش تهدید سایبری (CTI) موجود، یکپارچگی با زیرساختهای فعلی سازمان را فراهم میکند. این ادغام به سازمانها اجازه میدهد تا دادههای OntoLogX را با سایر منابع امنیتی ترکیب کنند و یک دید کلی از تهدیدات داشته باشند. همچنین، قابلیت API این سیستم، امکان توسعه و سفارشیسازی توسط تیمهای فنی را افزایش میدهد.
چالشها و محدودیتهای کنونی
هرچند OntoLogX عملکرد چشمگیری دارد، اما چند چالش باقی است:
وابستگی به کیفیت دادهی ورودی
اگر لاگها ناقص، دستکاریشده، یا شامل دادههای ناسازگار باشند، مدل نیز ممکن است برداشت اشتباه کند و تحلیلهای نادرست ارائه دهد. این مشکل بهویژه در محیطهایی با لاگهای قدیمی یا سیستمهای ناهمگن تشدید میشود، که نیازمند فیلترهای پیشرفتهتر و پیشپردازش دادهها است تا کیفیت ورودی بهبود یابد.
هزینه محاسباتی بالای LLMها
اجرای مدلهای زبانی بزرگ در مقیاس وسیع نیازمند منابع سختافزاری قدرتمند مانند GPUهای پیشرفته یا سرورهای ابری است، که هزینههای عملیاتی را افزایش میدهد. این چالش برای سازمانهای کوچک یا متوسط که بودجه محدودی دارند، میتواند مانعی باشد، و نیازمند بهینهسازیهای بیشتر در مصرف انرژی و منابع است.
نیاز به بهروزرسانی آنتولوژیها
تهدیدهای جدید به سرعت ظاهر میشوند و آنتولوژی باید بهروز بماند تا معنابخشی دقیق به دادهها انجام شود. این فرآیند نیازمند نظارت مداوم و همکاری با کارشناسان امنیتی است تا تعاریف جدید به آنتولوژی اضافه شوند، که میتواند زمانبر و پیچیده باشد.
آینده OntoLogX: از تحلیل تا پیشبینی
پژوهشگران برنامه دارند در نسخههای آینده، OntoLogX را از یک ابزار تحلیلی به یک عامل پیشبینیگر خودمختار تبدیل کنند؛ عاملی که بتواند نهتنها حملات گذشته را توضیح دهد، بلکه با تحلیل روندها و الگوهای تاریخی، احتمال وقوع حملات آینده را نیز پیشبینی کند. این قابلیت شامل استفاده از مدلهای پیشبینی آماری و یادگیری تقویتی است تا سناریوهای محتمل را شبیهسازی کند. همچنین، ادغام OntoLogX با مدلهای مولد گراف و سیستمهای CTI جهانی میتواند زمینهساز یک اکوسیستم هوش سایبری اشتراکی شود که دادهها را بهصورت جهانی به اشتراک میگذارد و همکاری بینالمللی را در مبارزه با تهدیدات سایبری تقویت میکند.
نتیجهگیری
نتیجهگیری کلی
پروژه FINEOntoLogX نقطه عطفی در مسیر هوش مصنوعی امنیتی است. این سیستم نشان میدهد که چگونه ترکیب مدلهای زبانی بزرگ، آنتولوژیها و گرافهای دانش میتواند از دادههای خام، بینشی عمیق و قابلاقدام خلق کند. در دنیایی که تهدیدها هر روز پیچیدهتر میشوند، OntoLogX نهتنها ابزاری برای تحلیل گذشته، بلکه گامی به سوی امنیت سایبری آیندهنگر است؛ جایی که ماشینها به جای صرفاً شناسایی تهدید، آنها را درک و پیشبینی میکند.
نقش در امنیت سایبری آیندهنگر
در دنیایی که تهدیدات سایبری هر روز پیچیدهتر و متنوعتر میشوند، OntoLogX فراتر از یک ابزار تحلیل گذشته عمل میکند و گامی محکم به سوی امنیت سایبری آیندهنگر است. این سیستم با توانایی درک عمیق الگوها و پیشبینی رفتارهای احتمالی مهاجمان، به سازمانها کمک میکند تا پیش از وقوع آسیب، اقدامات پیشگیرانه انجام دهند. این قابلیت بهویژه در برابر تهدیدات پیشرفته و مداوم (APT) که نیاز به استراتژیهای پیشبینیشده دارند، اهمیت دارد. همچنین، با ادغام با فناوریهای نوظهور مانند هوش مصنوعی مولد، OntoLogX میتواند سناریوهای فرضی را شبیهسازی کند و آمادگی دفاعی را تقویت کند.
جایگاه ماشینها در درک تهدیدات
OntoLogX جایی است که ماشینها دیگر صرفاً به شناسایی تهدیدات محدود نمیشوند، بلکه آنها را درک کرده و پیشبینی میکنند. این سیستم با استفاده از گرافهای دانش، زمینهای را برای ماشینها فراهم میکند تا روابط پیچیده بین رویدادها را تحلیل کنند و حتی با همکاری انسان، استراتژیهای دفاعی هوشمندانهای طراحی کنند. این تحول، همکاری انسان و ماشین را به سطح جدیدی میبرد و میتواند به ایجاد یک اکوسیستم امنیتی پویا منجر شود که در آن ماشینها نقش فعالتری در حفاظت از زیرساختهای حیاتی ایفا میکنند. با توجه به تاریخ امروز (19 اکتبر 2025)، این پیشرفت نشاندهنده جهشی بزرگ در صنعت امنیت سایبری است که میتواند پایهای برای نوآوریهای آینده باشد.
-
🔗منبع