کالبدشکافی دو رویکرد متضاد در یادگیری ماشین: آیا مدلها باید همهچیزدان باشند یا همهچیزدانها را بشناسند؟
<p> یادگیری درون-ابزاری در مقابل یادگیری درون-وزنی مدلهای زبان بزرگ (LLMs) در حال تجربهی یک دگردیسی بنیادین هستند. آنها از پیشبینیکنندههای ایستا که صرفاً متن تولید میکردند، به سیستمهایی پویا و آگاه از زمینه تبدیل شدهاند که میتوانند استدلال کنند، سازگار شوند و در دنیای دیجیتال دست به عمل بزنند. این تحول عظیم، با […]</p>
 مقالات
مقالات
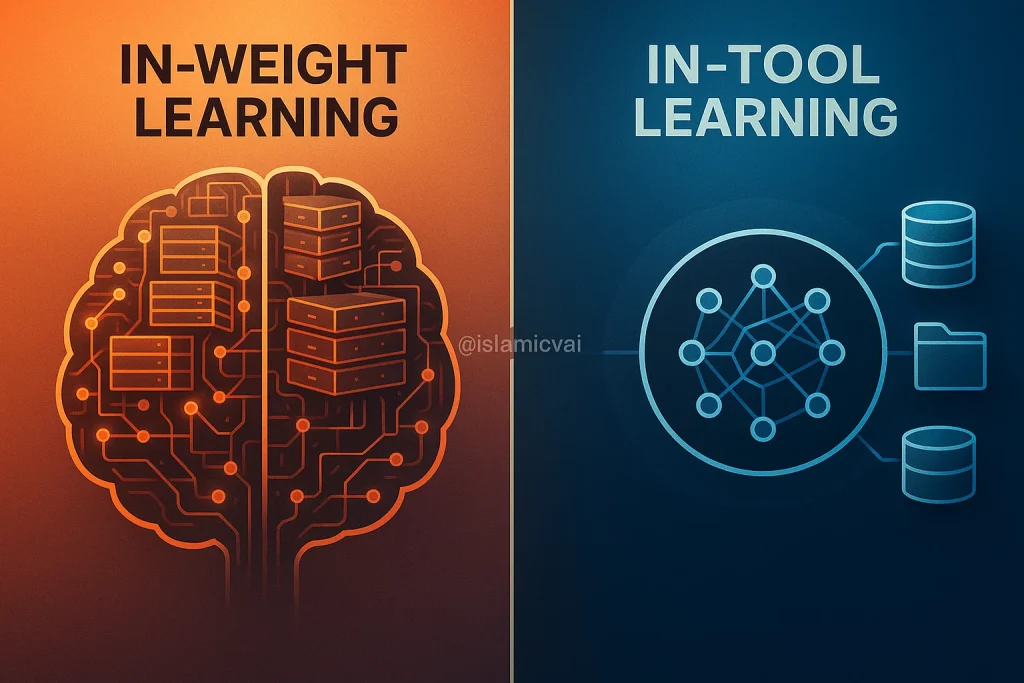
یادگیری درون-ابزاری در مقابل یادگیری درون-وزنی
مدلهای زبان بزرگ (LLMs) در حال تجربهی یک دگردیسی بنیادین هستند. آنها از پیشبینیکنندههای ایستا که صرفاً متن تولید میکردند، به سیستمهایی پویا و آگاه از زمینه تبدیل شدهاند که میتوانند استدلال کنند، سازگار شوند و در دنیای دیجیتال دست به عمل بزنند. این تحول عظیم، با ظهور قابلیتهایی مانند تولید مبتنی بر بازیابی تقویتی (RAG) و استفاده از حافظههای خارجی، در حال شکل دادن به آینده هوش مصنوعی است. اما این تکامل یک سوال استراتژیک و حیاتی را برای معماری سیستمهای هوشمند مطرح میکند: بهترین راه برای کسب، ذخیره و استفاده از دانش برای یک مدل هوش مصنوعی چیست؟ آیا باید انبوهی از حقایق جهان را مستقیماً در میلیاردها پارامتر مدل “حفظ” و فشرده کرد، یا باید به او یاد داد که چگونه به منابع خارجی حقیقت (ابزارها) دسترسی پیدا کرده و از آنها به صورت پویا استفاده کند؟
این مقاله به کالبدشکافی عمیق این دو رویکرد متضاد میپردازد: یادگیری درون-وزنی (In-Weight Learning)، که در آن اطلاعات در طول فرآیند آموزش در پارامترهای مدل رمزگذاری میشود، و یادگیری درون-ابزاری (In-Tool Learning)، که در آن مدل یاد میگیرد با منابع خارجی مانند پایگاههای داده یا APIها تعامل داشته باشد. یک پژوهش جدید با ارائه شواهد نظری و تجربی قوی، نشان میدهد که چرا رویکردهای مبتنی بر ابزار نه تنها یک انتخاب عملی، بلکه به طور اثباتشدهای مقیاسپذیرتر، کارآمدتر و برای حفظ قابلیتهای اصلی مدل، امنتر هستند.

دو فلسفه یادگیری: ذخیره در پارامترها یا دسترسی به ابزار؟ ⚖️
برای درک بهتر این موضوع، میتوانیم این دو رویکرد را با دو سبک یادگیری در انسان مقایسه کنیم:
- یادگیری درون-وزنی (فلسفه حفظ کردن): در این مدل، تمام دانش جهان باید در وزنهای شبکه عصبی رمزگذاری و فشرده شود. این مانند دانشآموزی است که سعی میکند کل یک دایرةالمعارف را کلمه به کلمه حفظ کند. اگرچه او ممکن است در پاسخ به سوالاتی که قبلاً حفظ کرده بسیار سریع باشد، اما ظرفیت حافظهاش به طور بنیادین محدود است. مهمتر از آن، یادگیری اطلاعات جدید و بهروزرسانی دانش قبلی، فرآیندی بسیار پرهزینه است و اغلب منجر به تداخل و فراموشی اطلاعات قدیمیتر میشود؛ پدیدهای که در علوم اعصاب و هوش مصنوعی به آن “فراموشی فاجعهبار” (Catastrophic Forgetting) میگویند.
- یادگیری درون-ابزاری (فلسفه استفاده از ابزار): در این مدل، هوش مصنوعی به جای حفظ کردن خودِ اطلاعات، یاد میگیرد که چگونه از ابزارهای خارجی (مانند یک پایگاه داده یا یک موتور جستجو) برای یافتن اطلاعات در لحظه استفاده کند. این مانند دانشآموزی است که به جای حفظ کردن دایرةالمعارف، طرز استفاده ماهرانه از کتابخانه، اینترنت و پایگاههای داده علمی را یاد میگیرد. ظرفیت دانش او تقریباً نامحدود و همیشه بهروز است، پاسخهایش قابل تفسیر و راستیآزمایی است (چون منبع اطلاعات مشخص است)، اما ممکن است برای یافتن هر پاسخ به دلیل نیاز به یک مرحله جستجوی اضافی، زمان بیشتری صرف کند.
این پژوهش به صورت نظری و عملی نشان میدهد که چرا فلسفه دوم، یعنی استفاده از ابزار، مسیری بسیار پایدارتر و مقیاسپذیرتر برای آینده هوش مصنوعی است.
اثبات ریاضی برتری: محدودیتهای بنیادی حفظ کردن و پتانسیل نامحدود ابزارها M
یکی از بزرگترین نوآوریهای این تحقیق، ارائه یک چارچوب نظری دقیق برای این مسئله است. محققان با استفاده از ریاضیات، دو قضیه کلیدی را به اثبات رساندهاند که به طور قطعی برتری یادگیری درون-ابزاری را نشان میدهد:
- قضیه حد پایین برای یادگیری درون-وزنی (Theorem 3.2): این قضیه به طور ریاضی ثابت میکند که تعداد حقایقی که یک مدل میتواند صرفاً در وزنهای خود ذخیره کند، به طور مستقیم و به صورت خطی به تعداد پارامترهای آن محدود است. این یک نتیجه بسیار قدرتمند است و به این معناست که برای دو برابر کردن تعداد حقایقی که یک مدل میتواند به خاطر بسپارد، شما باید تقریباً تعداد پارامترهای آن را نیز دو برابر کنید. این یک سقف ظرفیت سخت و یک تنگنای ساختاری برای رویکرد مبتنی بر حفظ کردن ایجاد میکند. مهم نیست مدل چقدر بزرگ باشد، ظرفیت آن برای ذخیره دانش همیشه محدود و هزینهبر خواهد بود.
- قضیه حد بالا برای یادگیری درون-ابزاری (Theorem 4.2): در مقابل، این قضیه ثابت میکند که یک ترانسفورمر با تعداد پارامترهای ثابت و نسبتاً کم (مثلاً تنها با ۸ لایه) میتواند به طور بالقوه تعداد نامحدودی از حقایق را بازیابی کند، به شرطی که یاد بگیرد چگونه به درستی یک پایگاه داده خارجی را مورد پرسش قرار دهد. محققان حتی یک “ساختار مداری” (circuit construction) دقیق طراحی کردهاند که به صورت الگوریتمی نشان میدهد چگونه یک مدل کوچک میتواند یک سوال را تجزیه کند، یک درخواست ابزار ساختاریافته ایجاد نماید، نام را از سوال کپی کرده و در نهایت پاسخ دریافت شده از ابزار را در یک جمله کامل و طبیعی قالب بندی کند. این یک اثبات وجودی قدرتمند است که نشان میدهد مقیاسپذیری دانش در این رویکرد، از اندازه مدل مستقل است و به جای بزرگ کردن مدل، باید بر روی آموزش مهارت تعامل با ابزار تمرکز کرد.
از تئوری تا عمل: نتایج آزمایشهای کنترلشده 🔬
برای تأیید این یافتههای نظری، محققان ترانسفورمرهای کوچکی را از ابتدا بر روی مجموعه دادههای مصنوعی از حقایق بیوگرافی آموزش دادند. نتایج تجربی به طور کامل و با دقت خیرهکنندهای با تئوریها همخوانی داشت:
- رشد خطی در مقابل اشباع: همانطور که پیشبینی میشد، در حالت یادگیری درون-وزنی، با افزایش تعداد حقایق، اندازه مدل مورد نیاز برای دستیابی به دقت بالا به طور مداوم و تقریباً خطی افزایش مییافت. اما در حالت یادگیری درون-ابزاری، یک “گذار فاز” (phase transition) جالب و تعیینکننده رخ داد: پس از رسیدن به یک نقطه بحرانی (حدود ۱۰۰۰ حقیقت در این آزمایش)، اندازه مدل مورد نیاز ثابت ماند و دیگر رشد نکرد. این نقطه اشباع، لحظهای است که مدل از تلاش برای حفظ کردن بیرویه دست برداشته و قانون کلی استفاده از ابزار را “درک” میکند.
- پدیده “گراک کردن” (Grokking): این گذار فاز، مشابه پدیده “grokking” است؛ یک تغییر ناگهانی و تأخیری از حفظ کردن کورکورانه به تعمیم سیستماتیک. قبل از این نقطه، مدلهای درون-ابزاری نیز مانند مدلهای درون-وزنی سعی در حفظ کردن داشتند و در نتیجه در مواجهه با دادههای جدید عملکرد ضعیفی از خود نشان میدادند. اما پس از عبور از این آستانه، آنها قاعده کلی ساخت درخواست برای ابزار را یاد گرفتند و توانستند این مهارت را به پایگاههای داده کاملاً جدید نیز تعمیم دهند، که نشاندهنده یادگیری یک مهارت واقعی و قابل انتقال است.
پیامدهای عملی برای مدلهای بزرگ: نبرد با فراموشی فاجعهبار 💥
مهمترین بخش این پژوهش، بررسی این مفاهیم بر روی مدلهای زبان بزرگ از پیش آموزشدیده مانند Llama و SmolLM است. نتایج این بخش پیامدهای عملی بسیار مهمی برای توسعهدهندگان و آینده مهندسی هوش مصنوعی دارد:
- فراموشی فاجعهبار در یادگیری درون-وزنی: زمانی که یک مدل بزرگ برای یادگیری حقایق جدید به روش درون-وزنی فاینتون (fine-tune) میشود، عملکرد آن در تواناییهای عمومی زبان (که با معیار استاندارد HellaSwag سنجیده میشود) به طور قابل توجهی کاهش مییابد. این پدیده به این دلیل رخ میدهد که پارامترهای مدل ظرفیت محدودی دارند و برای رمزگذاری اطلاعات جدید، ناچارند دانش قبلی را که در طول پیشآموزش یاد گرفتهاند، بازنویسی کرده یا با آن تداخل پیدا کنند. این افت عملکرد به خصوص در مدلهای کوچکتر و با افزایش تعداد حقایق جدید، شدیدتر و فاجعهبارتر است.
- حفظ توانایی در یادگیری درون-ابزاری: در مقابل، زمانی که همان مدل برای یادگیری نحوه استفاده از یک ابزار فاینتون میشود، تواناییهای عمومی آن تقریباً بدون تغییر باقی میماند. از آنجایی که دانش واقعی در خارج از مدل ذخیره میشود، فرآیند یادگیری با دانش قبلی تداخلی ایجاد نمیکند و مدل میتواند هم مهارت جدید را بیاموزد و هم قابلیتهای استدلال عمومی خود را حفظ کند.
علاوه بر این، یادگیری یک قانون کلی برای استفاده از ابزار به طور قابل توجهی از نظر محاسباتی کارآمدتر است و به مراحل آموزشی بسیار کمتری نسبت به حفظ کردن هزاران حقیقت مجزا نیاز دارد.
نتیجهگیری: پارادایم آینده؛ از انباشت دانش به ارکستراسیون اطلاعات 🚀
این پژوهش به طور جامع و با شواهد قوی نظری و تجربی، برتری یادگیری درون-ابزاری را بر یادگیری درون-وزنی برای بازیابی حقایق به اثبات میرساند. نتایج به وضوح نشان میدهند که تلاش برای افزایش ظرفیت دانش از طریق بزرگتر کردن مدلها، ذاتاً ناکارآمد، پرهزینه و دارای محدودیتهای بنیادین است. در مقابل، مدلهایی که یاد میگیرند با ابزارهای خارجی تعامل داشته باشند، میتوانند به دانش نامحدود دسترسی پیدا کنند بدون آنکه نیاز به افزایش تعداد پارامترهایشان داشته باشند و مهمتر از آن، بدون آنکه قابلیتهای استدلال عمومی خود را فدا کنند.
این یافتهها یک بینش طراحی کلیدی را برجسته میکنند: مدلهای زبان بزرگ نه با درونیسازی هرچه بیشتر اطلاعات، بلکه با یادگیری نحوه دسترسی، پردازش و ارکستراسیون آن، به طور مؤثرتری مقیاسپذیر میشوند. آینده هوش مصنوعی کمتر به ساخت مدلهای یکپارچه و غولپیکر که همه چیز را میدانند شباهت دارد و بیشتر به سمت سیستمهای ماژولار و چابکی میرود که در تعامل با منابع خارجی ساختاریافته تخصص دارند.