تحلیل معماری، شکستهای سیستمی و مسیرهای اصلاح در عاملهای مبتنی بر LLM
تائهیون کیم (Taeyoon Kim)
ووهیوک پارک (Woohyeok Park)
هویئونگ یون (Hoyeong Yun)
کیونگیونگ لی (Kyungyong Lee)
چکیده
در سامانههای ابری مقیاسبالا، خرابیها میتوانند زیانهای مالی قابلتوجهی ایجاد کنند و به همین دلیل تحلیل ریشهای خطا (RCA) به یک ضرورت عملیاتی تبدیل شده است. در سالهای اخیر، استفاده از عاملهای مبتنی بر مدلهای زبانی بزرگ (LLM) برای خودکارسازی این فرآیند رشد چشمگیری داشته، اما عملکرد عملی این عاملها همچنان
در سامانههای ابری بزرگ، هر خطا میتواند منجر به توقف سرویس و زیان مالی قابل توجه شود؛ ازاینرو «تحلیل ریشهای خطا» یا RCA به یک ضرورت عملیاتی تبدیل شده است. در این پژوهش، بنچمارک OpenRCA را به طور کامل روی پنج مدل زبانی بزرگ اجرا کردند و در مجموع ۱،۶۷۵ بار عامل هوش مصنوعی را به کار گرفتند. اما بهجای اینکه فقط ببینند پاسخ نهایی درست است یا نه، بررسی کردند که این عاملها دقیقاً در کجای مسیر تحلیل و به چه دلیل دچار خطا میشوند. نتایج نشان میدهد که نرخ تشخیص کامل بین ۳.۹٪ تا ۱۲.۵٪ متغیر است و خطاهای غالب—بهویژه «توهم در تفسیر داده» (۷۱.۲٪) و «اکتشاف ناقص» (۶۳.۹٪)—در همه مدلها تکرار میشوند. این الگو نشان میدهد ریشه شکستها در معماری مشترک عاملهاست، نه صرفاً در توان مدلها. آزمایشهای کاهش خطا نشان میدهد مهندسی پرامپت بهتنهایی کافی نیست، اما غنیسازی ارتباط میان عاملها میتواند خطاهای ارتباطی را تا ۱۵ واحد درصد کاهش دهد. این مقاله با ارائه یک طبقهبندی ۱۲گانه از دامهای معماری، چارچوبی نظاممند برای طراحی عوامل قابلاعتماد در عملیات ابری فراهم میکند.
۱. مقدمه
در سرویسهای توزیعشده بزرگ، خرابی یک مؤلفه میتواند بهصورت زنجیرهای در کل سامانه منتشر شود و نشانههایی گمراهکننده ایجاد کند. تحلیل ریشهای خطا فرآیندی است که طی آن باید مؤلفه معیوب، زمان وقوع خطا و دلیل آن مشخص شود. این کار نیازمند همبستگی میان سه نوع داده تلهمتری است: متریکها (مانند مصرف CPU و حافظه)، لاگهای متنی و ردگیریهای توزیعشده. هر کدام تنها بخشی از تصویر سیستم را نشان میدهند و بدون تحلیل مشترک آنها، تشخیص دقیق ممکن نیست. به همین دلیل، این حوزه سنتاً وابسته به مهندسان خبره با دانش عمیق دامنه بوده است.
با ظهور مدلهای زبانی بزرگ، معماریهای چندعاملی برای خودکارسازی RCA توسعه یافتند. در بنچمارک OpenRCA، ۳۳۵ حادثه در سه دامنه Telecom، Bank و Market با ۷۳ مؤلفه و ۲۸ نوع خطا بررسی شدهاند. با وجود این زیرساخت گسترده، حتی بهترین مدل تنها به ۱۲.۵٪ تشخیص کامل رسیده است. چارچوبهای ارزیابی موجود فقط صحت پاسخ نهایی را میسنجند و توضیح نمیدهند چرا استدلال عامل شکست خورده است. این پژوهش با تمرکز بر تحلیل فرایندی شکست، این خلأ را پر میکند و ریشههای معماری خطا را آشکار میسازد.
۲. عامل LLM برای RCA
در معماری OpenRCA، دو عامل اصلی وجود دارد: «کنترلکننده» که استدلال سطح بالا را انجام میدهد و «اجراکننده» که دستورها را به کد پایتون تبدیل کرده و روی دادههای تلهمتری اجرا میکند. این معماری Controller–Executor با هدف کاهش پیچیدگی طراحی شده است. دادهها شامل ۶۸.۵ گیگابایت اطلاعات و بیش از ۵۲۳ میلیون خط هستند که در سه مدالیته ارائه میشوند. کنترلکننده با تولید دستورهای زبان طبیعی، مسیر تحلیل را تعیین میکند و اجراکننده نتایج را بازمیگرداند. 🔄
با وجود این ساختار، دقت تشخیص بسیار پایین باقی مانده است. برای تشخیص کامل باید سه عنصر مؤلفه، زمان و دلیل خطا همزمان درست شناسایی شوند. تفاوت میان «تشخیص کامل» و «جزئی» نشان میدهد بسیاری از اجراها تنها بخشی از ریشه را یافتهاند. این مسئله نشان میدهد مشکل فقط در توان استدلال مدل نیست، بلکه در نحوه تعامل عاملها و مدیریت داده نیز نهفته است. 📉
جدول ۱: مقایسه دقت عامل پایه OpenRCA در سه دامنه خدماتی
| مدل | کل (%) | مخابرات (%) | بانک (%) | بازار (%) | ||||
|---|---|---|---|---|---|---|---|---|
| ● | ▲ | ● | ▲ | ● | ▲ | ● | ▲ | |
| Gemini 2.5 Pro | 12.5 | 22.4 | 11.8 | 13.7 | 19.9 | 19.9 | 6.1 | 27.7 |
| GPT-5 mini | 8.4 | 21.5 | 15.7 | 21.6 | 11.8 | 16.2 | 2.7 | 26.4 |
| GPT-OSS 120B | 6.9 | 12.2 | 9.8 | 15.7 | 7.4 | 11.8 | 5.4 | 11.5 |
| Solar Pro 2 | 5.7 | 15.8 | 9.8 | 11.8 | 6.6 | 15.4 | 3.4 | 17.6 |
| Claude Sonnet 4 | 3.9 | 14.3 | 5.9 | 7.8 | 4.4 | 15.4 | 2.7 | 15.5 |
| Claude Sonnet 3.5* | 11.3 | 17.3 | – | – | – | – | – | – |
* نتایج برگرفته از پژوهش اصلی RCA-Agent [8]
● تشخیص کامل | ▲ تشخیص نسبی
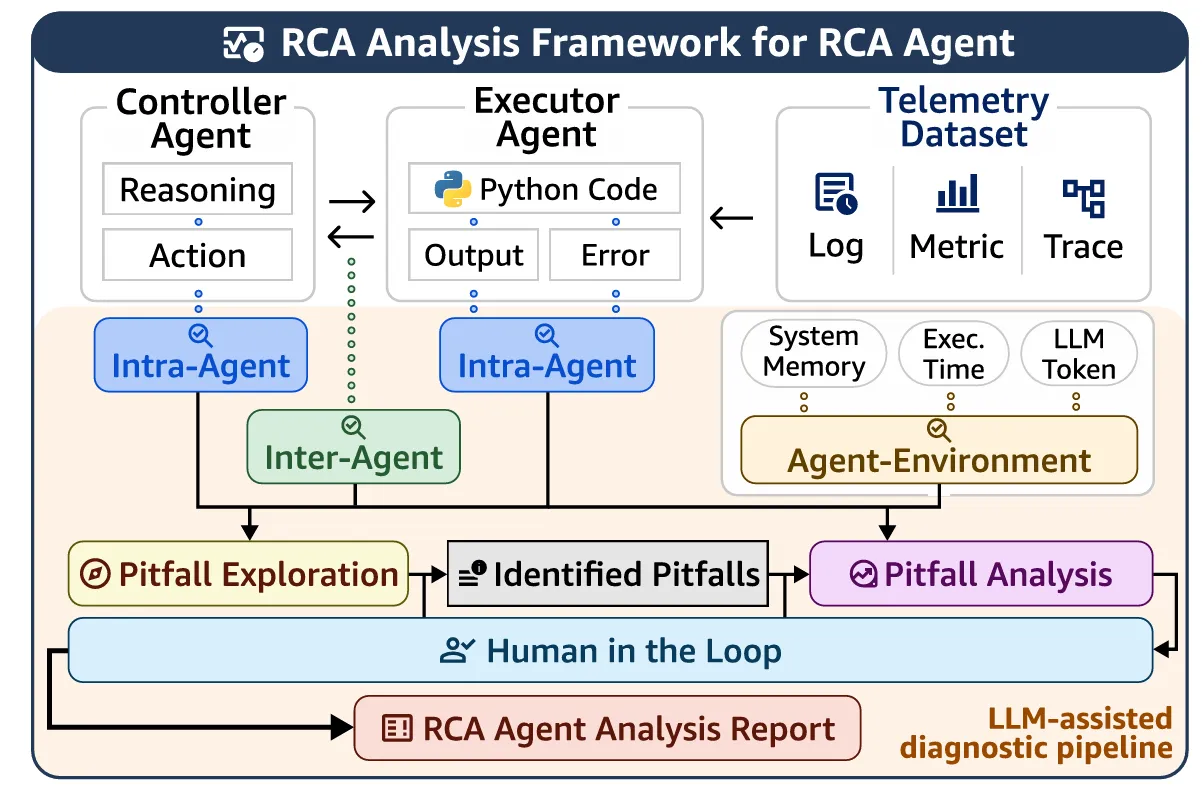
شکل ۱: چارچوب تحلیلی برای شناسایی شکستهای عامل RCA در سه رابط
۳. روششناسی تشخیص شکست عامل
برای تحلیل نظاممند علل عملکرد پایین، چارچوبی سهلایه طراحی شد که شکستها را بر اساس منشأ معماری آنها طبقهبندی میکند: استدلال درونعاملی، ارتباط میانعاملی و تعامل عامل با محیط اجرا. این تقسیمبندی امکان میدهد مشخص شود خطا ناشی از منطق داخلی عامل است، از انتقال ناقص معنا میان نقشها سرچشمه میگیرد یا از محدودیتهای زیرساخت اجرایی ایجاد میشود. در مجموع، 1,675 اجرای عامل بر بستر بنچمارک OpenRCA بررسی شد که هر اجرا به طور میانگین 11.1 گام داشت و در مجموع 609.9 ساعت زمان دیواری مصرف کرد. همچنین این اجراها حدود 1.38 میلیارد توکن API مصرف کردند که نشاندهنده مقیاس بالای تحلیل تجربی است. ⏱️
تحلیل در دو مرحله مکمل انجام شد تا سوگیری دستهبندی کاهش یابد. در مرحله نخست، الگوهای شکست بهصورت اکتشافی و بدون چارچوب از پیشتعیینشده استخراج شدند تا تنوع واقعی خطاها نمایان شود. سپس در مرحله دوم، این الگوها در قالب 12 دام مشخص با معیارهای تشخیصی دودویی تثبیت شدند؛ برای مثال پرسشهایی مانند «آیا عامل یک KPI مرتبط را نادیده گرفت؟». این رویکرد، علاوه بر افزایش تکرارپذیری، امکان مقایسه میان مدلها و تعیین فراوانی نسبی هر دام را فراهم کرد و پایهای تجربی برای طراحی مداخلات معماری ایجاد نمود. 🧪
۴. مشکلات معماری در عوامل RCA
تحلیل فراگیر نشان داد دامهای شناساییشده در همه مدلها با فراوانی بالا تکرار میشوند و الگوی توزیع آنها شباهت ساختاری دارد. این همگرایی آماری نشان میدهد منشأ اصلی شکستها در معماری مشترک عامل نهفته است، نه در تفاوت سطح توان مدلها یا ارائهدهندگان آنها. برای نمونه، برخی دامها در همه مدلها بیش از 66٪ فراوانی داشتهاند که بیانگر یک محدودیت سیستماتیک است. 📊
سه سطح شکست شامل: درونعاملی (استدلال داخلی کنترلر)، میانعاملی (رابط ارتباطی کنترلر و اجراکننده) و عامل-محیط (مدیریت حافظه، گامها و وضعیت هسته اجرا) هستند. این سه سطح در کنار هم یک چارچوب تشخیصی کامل ایجاد میکنند که امکان میدهد بفهمیم آیا مشکل از منطق تولید متن است، از فشردهسازی زبان طبیعی در انتقال پیام ناشی میشود یا از ناهماهنگی با وضعیت اجرایی سیستم سرچشمه میگیرد. 🔍
۴.۱ مشکلات درون-عاملی
شایعترین خطا «توهم در تفسیر داده» با نرخ 71.2٪ بود؛ در این حالت، کنترلر به جای خوانش وفادارانه مقادیر بازگشتی، روایتی منسجم اما نامنطبق با دادهها تولید میکند. این الگو با سوگیری مولد مدلهای زبانی سازگار است که تمایل دارند شکافهای اطلاعاتی را با روایتهای plausibly coherent پر کنند. «اکتشاف ناقص» با 63.9٪ نیز نشان میدهد عامل دامنه بررسی را محدود میکند و برخی KPIها یا مؤلفههای کاندید را اساساً وارد چرخه تحلیل نمیکند. 📈
«علامت به جای علت» (39.9٪) بیانگر توقف زودهنگام در زنجیره علّی است؛ عامل نخستین ناهنجاری مشاهدهشده را بهعنوان علت ریشهای میپذیرد بدون آنکه وابستگیهای بالادستی را دنبال کند. «عدم اعتبارسنجی متقابل» (18.6٪) نیز نشان میدهد یافتهها با منابع دیگر مانند لاگ یا تریس مقایسه نمیشوند. علاوه بر این، خطاهای تولید کد (27.2٪) و خطای زمانی (23.3٪) به محدودیتهای اجرایی و ناسازگاری زمانی دادهها مربوطاند. با وجود تفاوت شدت برخی دامها میان مدلها، دو دام توهم تفسیری و اکتشاف ناقص در همه آنها پایدار و بالا باقی ماندهاند که ماهیت ساختاری مسئله را برجسته میکند. ⚠️
۴.۲ مشکلات میان-عاملی
در این معماری، کنترلر و اجراکننده تنها از طریق خلاصههای زبان طبیعی با یکدیگر تعامل دارند و هیچیک به زمینه کامل داخلی دیگری دسترسی ندارد. «ناهمخوانی دستور و کد» که بین 20 تا 26٪ گامها رخ داده، زمانی ایجاد میشود که اجراکننده مقصود تحلیلی کنترلر را بهدرستی بازسازی نکند و کدی تولید کند که به پرسشی متفاوت پاسخ دهد. این خطا محصول فشردهسازی معنایی در انتقال پیام است. 🔄
«تکرار بیمعنا» (تا 17.6٪) زمانی مشاهده میشود که کنترلر به دلیل نداشتن دید کامل از تاریخچه شکستها، همان دستور ناموفق را تکرار میکند و وارد چرخهای مصرفکننده گام میشود. «انتساب نادرست شواهد» نیز ناشی از آن است که کنترلر تنها خلاصهای از خروجی را میبیند و به کد اجراشده دسترسی ندارد؛ بنابراین ممکن است نتیجهای را معتبر بداند که بر اجرای نادرست مبتنی بوده است. این الگوها نشان میدهد محدودیت رابط ارتباطی یکی از گلوگاههای کلیدی عملکرد عاملهای چندنقشی است. 📡
۴.۳ مشکلات عامل-محیط
سیستم از یک هسته پایتون پایدار برای کاهش تأخیر و جلوگیری از بارگذاری مکرر داده استفاده میکند، اما عامل از وضعیت انباشته حافظه در این هسته آگاه نیست. در برخی سناریوها، بارگذاری مجدد دادههای حجیم یا عدم آزادسازی متغیرهای قدیمی منجر به خطای Out-of-Memory شده و کل جلسه تشخیص را متوقف کرده است. این نوع شکست ماهیت دودویی دارد و فارغ از کیفیت استدلال، اجرای کامل را خاتمه میدهد. 💾
«اتمام حداکثر گام» نیز در 4.1٪ اجراها مشاهده شد و در برخی مدلها نرخ بالاتری داشت. این پدیده میتواند ناشی از مصرف ناکارآمد گامها یا تلاش برای اکتشاف گستردهتر باشد، اما در هر صورت به محدودیت بودجه اجرایی منتهی میشود. این یافتهها اهمیت جداسازی و مدیریت صریح وضعیت محیط اجرا را در طراحی عاملهای RCA برجسته میکند. ⚙️
۵. کاهش مشکلات در عامل RCA
برای ارزیابی امکان بهبود، مداخلات بهصورت کنترلشده و تکمتغیره طراحی شدند تا اثر هر تغییر معماری بهطور مستقل سنجیده شود. هدف این بود که مشخص شود کدام دسته از دامها به اصلاح سطح پرامپت پاسخ میدهند و کدامیک نیازمند بازطراحی ساختاری هستند. نتایج نشان داد اصلاحات معماری اثرگذاری معنادارتری نسبت به تغییرات صرفاً زبانی دارند. 🧩
این رویکرد تجربی، بهجای پیشنهاد یک سامانه جدید کامل، بر شناسایی نقاط شکست و آزمون هدفمند هر اصلاح تمرکز داشت؛ روشی که امکان تعمیم یافتهها به چارچوبهای مشابه را فراهم میکند و از اغراق در نتایج جلوگیری مینماید. 📊
۵.۱ درون-عاملی: پارادوکسهای مهندسی پرامپت
دو رویکرد «پرامپت مبتنی بر فرضیه» و «پرامپت آگاه از دام» در مجموعهای از وظایف حوزه Bank آزمایش شد. رویکرد نخست عامل را ملزم میکرد برای هر خانواده KPI فرضیه صریح ارائه دهد و دامنه اکتشاف را گسترش دهد. رویکرد دوم توصیف دامهای رایج را به پرامپت افزود تا عامل از آنها پرهیز کند. 📌
اگرچه این تغییرات باعث افزایش پوشش شاخصها شدند، اما نرخ «توهم در تفسیر» تقریباً بدون تغییر باقی ماند. عامل به دادههای مرتبط دست یافت، اما همچنان روایتهایی تولید کرد که با مقادیر واقعی سازگار نبودند. این نتیجه نشان میدهد مشکل اصلی ریشه در فرایند مولد مدل دارد و با افزایش دستورالعملهای متنی بهتنهایی برطرف نمیشود. ❗
۵.۲ میان-عاملی: ارتباطات غنیشده
در این مداخله، اجراکننده علاوه بر خلاصه زبانی، کد کامل تولیدشده و خروجی اجرای آن، شامل پیامهای خطا و استکترِیس، را بازمیگرداند. بهطور متقابل، اجراکننده نیز به زمینه تحلیلی کامل کنترلر و بخشی از خروجی قبلی دسترسی پیدا کرد. این غنیسازی رابط ارتباطی باعث کاهش خطاهای میانعاملی تا 15 واحد درصد شد. 📉
در آزمایشهای حوزه Bank، تعداد تشخیصهای کامل در همه مدلها افزایش یافت. با وجود افزایش میانگین مصرف توکن در هر گام (24.8٪)، کاهش تعداد گامها منجر به کاهش 22.3٪ زمان اجرا و کاهش خالص مصرف کل توکن شد. این یافته نشان میدهد اصلاح ساختاری کانال ارتباطی میتواند همزمان دقت و کارایی را بهبود دهد؛ دستاوردی که مهندسی پرامپت بهتنهایی قادر به ایجاد آن نبود. 🚀
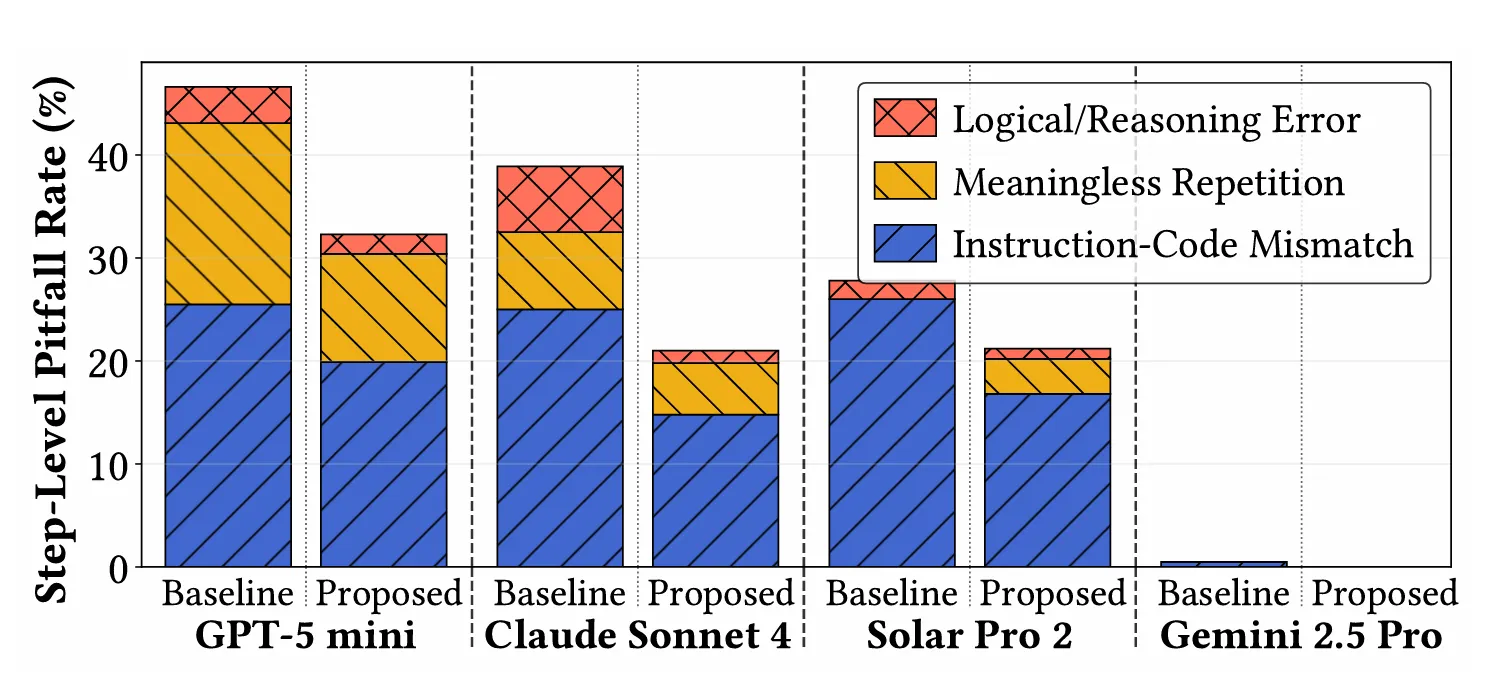
شکل ۲: نرخ خطاهای میانعاملی در سطح گام تحت ارتباط پایه و ارتباط غنیشده
۵.۳ عامل-محیط: جداسازی حالت مقاوم
برای جلوگیری از خطاهای حافظه، یک پایشگر مصرف حافظه به هسته اجرا افزوده شد که در صورت عبور از آستانه مشخص، اجرا را متوقف کرده و هشدار ساختاری به کنترلر ارسال میکند تا پیادهسازی کارآمدتری روی هسته بازنشانیشده تولید کند. اعتبارسنجی در همه مدلها نشان داد این مکانیزم تمام خطاهای OOM مشاهدهشده در پیکربندی پایه را حذف میکند. 🛡️
این مداخله نشان داد بخشی از شکستها نه به ضعف استدلال، بلکه به ناهماهنگی با محیط اجرا مربوطاند. بنابراین طراحی عاملهای خودکار RCA مستلزم مدیریت صریح و مقاوم وضعیت اجرایی است تا ارزیابی سایر بهبودها بدون تداخل خطاهای زیرساختی انجام شود. ⚙️
۶. نتیجهگیری
این پژوهش نشان داد شکست سیستماتیک عاملهای LLM در تحلیل ریشهای خطا عمدتاً ناشی از محدودیتهای معماری مشترک است، نه ضعف مدل منفرد. توهم در تفسیر (71.2٪) و اکتشاف ناقص (63.9٪) در همه مدلها پایدار باقی ماندهاند. 📊
مداخلات ساختاری، بهویژه غنیسازی ارتباط میان عاملها و پایش حافظه، بهبود معناداری در دقت و کارایی ایجاد کردند؛ در حالی که مهندسی پرامپت به تنهایی کافی نبود. مسیرهای آینده شامل طراحی ماژولهای اعتبارسنجی خارجی، اشتراک حالت ساختیافته و پایش مستمر الگوهای شکست است تا نسل بعدی عاملهای خودکار RCA قابلاعتمادتر شوند. 🌱