تحلیل کرنلهای گراف و GNNها برای افزایش توضیحپذیری نمایش گراف
۱. مقدمه
یادگیری نمایش گراف قابل توضیح یکی از موضوعات مهم و روبهرشد در حوزه هوش مصنوعی توضیحپذیر است که با هدف افزایش شفافیت، اعتمادپذیری و قابلیت تفسیر مدلهای یادگیری ماشین مطرح شده است 🤖📊. با گسترش استفاده از مدلهای پیچیده، بهویژه در حوزههایی که تصمیمات آنها پیامدهای مهمی دارند، نیاز به درک نحوه عملکرد این مدلها بیش از پیش احساس میشود. در بسیاری از کاربردهای حیاتی مانند زیستپزشکی، شیمی و شبکههای اجتماعی، دادهها بهصورت گراف نمایش داده میشوند و همین موضوع اهمیت تحلیل دقیق نمایشهای گرافی را دوچندان میکند.
در چنین کاربردهایی، صرف دستیابی به دقت بالا کافی نیست، بلکه باید مشخص شود که مدل دقیقاً چه اطلاعاتی را از ساختار و ویژگیهای گراف استخراج میکند و این اطلاعات چگونه در تصمیمگیری نهایی نقش دارند. پژوهش حاضر تمرکز خود را بر توضیحپذیری در سطح «نمایش گراف» قرار داده است، نه صرفاً توضیح خروجی مدل یا تحلیل یک نمونه خاص، و تلاش میکند به درک عمیقتری از محتوای نهفته در نمایشهای گرافی دست یابد.
در این مقاله، این پرسش اساسی مطرح میشود که نمایشهای گرافی دقیقاً چه اطلاعات ساختاری و چه نوع ویژگیهایی را در خود جای میدهند 🔍. ایده اصلی بر تحلیل الگوهای گرافی مانند مسیرها، درختها و چرخهها استوار است و هدف آن مشخصکردن سهم هر یک از این الگوها در فرآیند یادگیری نمایش نهایی گراف میباشد. با این رویکرد، میتوان ارتباط میان ساختار گراف و نمایش یادگرفتهشده را بهصورت شفافتری بررسی کرد.
این چارچوب تحلیلی با الهام از کرنلهای گرافی ارائه شده و تلاش میکند یک راهکار نظاممند و ساختارمند برای توضیحپذیری نمایش گراف فراهم آورد. چنین رویکردی زمینه را برای تحلیل نظری، طراحی مدلهای قابل اعتمادتر و استفاده ایمنتر از یادگیری گراف در کاربردهای حساس فراهم میسازد.
۲. نمادها
برای بیان دقیق مفاهیم و جلوگیری از ابهام در فرمولبندیها، در این مقاله از نمادگذاری ریاضی مشخص و یکپارچهای استفاده شده است ✏️📐. گراف بهصورت تعریف میشود که در آن V مجموعه گرهها و E مجموعه یالها را نشان میدهد. این تعریف، چارچوب اصلی نمایش دادههای گرافی را تشکیل میدهد و مبنای تمام تحلیلهای بعدی قرار میگیرد. ساختار گراف از طریق روابط میان گرهها و یالها توصیف میشود.
برای نمایش اتصالات میان گرهها، از ماتریس مجاورت با نماد A استفاده میشود و ویژگیهای گرهها در قالب ماتریس ویژگیها با نماد X نمایش داده میشوند. هر گراف در مجموعه داده، علاوه بر ساختار و ویژگیهای محلی، دارای یک نمایش برداری در سطح گراف است که با g نشان داده میشود. این نمایش برداری خلاصهای از اطلاعات کل گراف بوده و در وظایف یادگیری مورد استفاده قرار میگیرد.
همچنین زیرگرافها بهعنوان بخشهایی از گراف اصلی تعریف میشوند که برای تحلیل الگوهای ساختاری مورد استفاده قرار میگیرند 🧩. هر زیرگراف شامل مجموعهای از گرهها و یالهاست که بخشی از ساختار کلی گراف را بازنمایی میکند. این زیرگرافها نقش مهمی در استخراج و تحلیل الگوهای گرافی دارند.
الگوی گراف به مجموعهای از زیرگرافها با ویژگیهای ساختاری مشابه اشاره دارد، مانند مسیر، درخت یا گرافلت. این الگوها واحدهای اصلی تحلیل در یادگیری نمایش گراف محسوب میشوند و نمادگذاری آنها پایه تحلیلهای بعدی در فرآیند یادگیری و توضیحپذیری نمایش گراف را تشکیل میدهد.
۳. یادگیری توضیحپذیر گراف از طریق کرنل مجموعهای گراف
در این بخش، مفهوم یادگیری توضیحپذیر گراف با تکیه بر کرنلهای گراف بهصورت دقیق بررسی میشود 🧠. کرنل گراف بهعنوان ابزاری ریاضی، برای سنجش میزان شباهت بین دو گراف به کار میرود و این کار را از طریق شمارش الگوهای ساختاری مشترک انجام میدهد. در این چارچوب، هر گراف به یک بردار با بُعد بالا نگاشت میشود که هر مؤلفه آن نشاندهنده تعداد وقوع یک الگوی خاص در گراف است.
ایده محوری این رویکرد آن است که بهجای اتکا به یک الگوی واحد، چندین کرنل مبتنی بر الگوهای مختلف بهصورت همزمان مورد استفاده قرار گیرند 🔗. با ترکیب این کرنلها در قالب یک کرنل مجموعهای وزندار، میتوان سهم و نقش هر الگوی گرافی را در نمایش نهایی گراف مشخص کرد. وزنهای یادگرفتهشده مستقیماً بیانگر اهمیت هر الگو هستند و همین موضوع، توضیحپذیری نمایش گراف را بهطور طبیعی فراهم میکند.
۳.۱ کرنل شمارش الگو
کرنل شمارش الگو بر پایه شمارش تعداد وقوع هر زیرساختار مشخص در گراف تعریف میشود 🔢. برای هر الگوی گرافی، یک بردار شمارش ساخته میشود که هر مؤلفه آن بیانگر تعداد رخداد یک نمونه خاص از آن الگو در گراف است. این بردار، نمایش ساختاری گراف را بهشکلی صریح و قابل تفسیر ارائه میدهد.
شباهت بین دو گراف از طریق ضرب داخلی بردارهای شمارش آنها محاسبه میشود که نشان میدهد دو گراف تا چه اندازه از نظر الگوهای ساختاری مشترک هستند 📊. این رویکرد پایه بسیاری از کرنلهای شناختهشده گراف است و بهدلیل ماهیت شمارشی خود، ارتباط مستقیمی بین ساختار گراف و نمایش عددی آن برقرار میکند.
شکل ۱: نمونههایی از الگوهای گراف: Ppath، PT و Pgl.

۳.۲ تحلیل الگو با استفاده از کرنلهای گراف
با در اختیار داشتن چند کرنل مبتنی بر الگوهای متفاوت، امکان تحلیل دقیق سهم هر الگو در دادههای گرافی فراهم میشود ⚖️. در این روش، یک کرنل مجموعهای وزندار تعریف میشود که از ترکیب خطی کرنلهای منفرد تشکیل شده است. هر کرنل نماینده یک الگوی خاص است و وزن اختصاصیافته به آن، میزان اهمیت آن الگو را نشان میدهد.
این وزنها بهصورت خودکار و از طریق توابع زیان نظارتشده یا بدوننظارتشده یاد گرفته میشوند 🎯. در نتیجه، مدل نهتنها به شباهتسنجی یا یادگیری مؤثرتر دست مییابد، بلکه توضیح شفافی از اینکه کدام الگوهای گرافی نقش پررنگتری در نمایش گراف دارند نیز ارائه میدهد؛ موضوعی که برای تحلیل علمی و تفسیر نتایج بسیار ارزشمند است.
۳.۳ محدودیتهای بردار شمارش الگو
با وجود شفافیت و توضیحپذیری بالای بردار شمارش الگو، این روش با محدودیتهایی همراه است 🚧. نخستین محدودیت آن است که این بردار تنها ساختار توپولوژیکی گراف را در نظر میگیرد و ویژگیهای گرهها را نادیده میگیرد، در حالی که طبق نتایج پژوهشهای مرتبط، ویژگیهای گره نقش مهمی در یادگیری نمایش گراف دارند.
دومین محدودیت به توپولوژیکی مربوط میشود که باعث افزایش هزینههای محاسباتی و حافظهای میگردد ⏳. علاوه بر این، فرآیند شمارش الگوها زمانبر است و این نوع نمایشها قابلیت یادگیری ضمنی اطلاعات پیچیده و پنهان را ندارند؛ قابلیتی که شبکههای عصبی گراف از طریق پیامرسانی و یادگیری عمیق بهخوبی فراهم میکنند.
۴. یادگیری نمایشهای گراف قابل توضیح از طریق GNNها
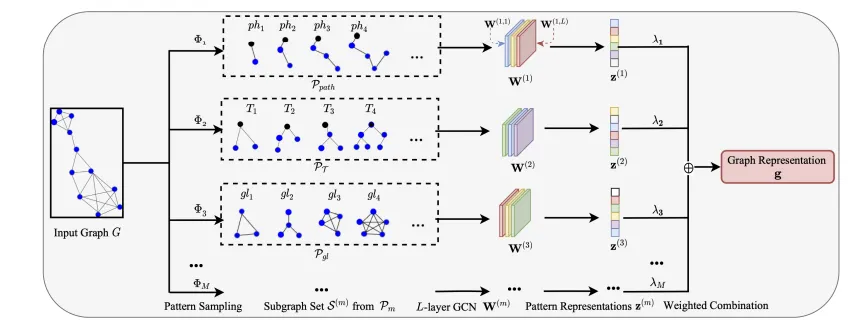
برای غلبه بر محدودیتهای مطرحشده در رویکردهای مبتنی بر کرنلهای گراف، یک چارچوب مبتنی بر شبکههای عصبی گراف (GNN) معرفی میشود 🧩🤖. در این چارچوب، بهجای استفاده مستقیم از بردارهای شمارش ثابت و از پیشتعریفشده، از قابلیت GNNها برای یادگیری نمایشهای غنی، پویا و قابل یادگیری استفاده میشود. این تغییر رویکرد امکان درنظرگرفتن همزمان ساختار گراف و ویژگیهای گرهها را فراهم میسازد.
در این روش، ابتدا زیرگرافهایی مطابق با الگوهای گرافی مختلف از گراف اصلی نمونهبرداری میشوند. این زیرگرافها نماینده بخشهای معنادار ساختار گراف هستند و بهعنوان ورودی به شبکههای عصبی گراف داده میشوند. در گام بعد، نمایش هر الگو بهصورت مستقل و با استفاده از یک تابع یادگیری مبتنی بر GNN استخراج میشود. در نهایت، نمایش کلی گراف بهصورت یک ترکیب وزندار از نمایش الگوها ساخته میشود 🎛️؛ بهگونهای که وزنها نقش محوری در توضیحپذیری دارند و بهطور مستقیم نشان میدهند کدام الگوهای گرافی بیشترین سهم را در شکلگیری نمایش نهایی گراف ایفا میکنند.
تعریف ۴.۱ (مجموعه نمونهبرداری الگو)
مجموعه نمونهبرداری الگو شامل تعدادی زیرگراف است که همگی به یک الگوی گرافی مشخص تعلق دارند 🔍. این زیرگرافها از گراف اصلی استخراج میشوند و هرکدام نمونهای از ساختار آن الگو در گراف محسوب میشوند. بدین ترتیب، هر الگو بهوسیله مجموعهای از زیرگرافهای نماینده توصیف میشود.
هدف اصلی از این فرآیند نمونهبرداری، کاهش پیچیدگی محاسباتی و تمرکز بر بخشهای معنادار و مرتبط گراف است 📉. از آنجا که ممکن است همپوشانی میان الگوهای مختلف وجود داشته باشد، از آزمون WL برای اطمینان از یکتایی زیرگرافهای نمونهبرداریشده استفاده میشود. این کار باعث افزایش دقت تحلیل و جلوگیری از تکرار اطلاعات میگردد.
تعریف ۴.۲ (نمایش الگو)
نمایش الگو با اعمال یک تابع یادگیری بر روی زیرگرافهای نمونهبرداریشده بهدست میآید 🧠. این تابع یادگیری که معمولاً یک شبکه عصبی گراف است، بهصورت همزمان ساختار توپولوژیکی زیرگراف و ویژگیهای گرههای آن را در فرآیند یادگیری لحاظ میکند.
برای بهدست آوردن یک نمایش واحد از هر الگو، نمایشهای استخراجشده از تمام زیرگرافها با یکدیگر تجمیع میشوند 📊. در این چارچوب، میانگینگیری از نمایش زیرگرافها بهعنوان نمایش نهایی الگو در نظر گرفته میشود که خلاصهای غنی و فشرده از اطلاعات ساختاری و ویژگیای آن الگو در گراف را ارائه میدهد.
تعریف ۴.۳ (نمایش ترکیبی)
نمایش ترکیبی گراف از جمع وزندار نمایشهای مربوط به الگوهای مختلف تشکیل میشود ⚙️. هر وزن نشاندهنده میزان مشارکت یک الگوی خاص در نمایش نهایی گراف است و این وزنها بهگونهای تنظیم میشوند که مجموع آنها برابر با یک باشد.
این ساختار ترکیبی باعث میشود که مدل بتواند اطلاعات استخراجشده از الگوهای متنوع را بهشکلی متعادل و قابل تفسیر ادغام کند 🔎. در نتیجه، علاوه بر بهبود عملکرد یادگیری، توضیحپذیری نمایش گراف نیز حفظ میشود و میتوان بهطور دقیق مشخص کرد کدام الگوها نقش کلیدیتری در تصمیمگیری مدل داشتهاند.
۵. تحلیل نظری
تحلیل نظری نقش اساسی در ارزیابی اعتبار، پایداری و قابل اتکا بودن روش پیشنهادی ایفا میکند 📐. در این بخش، مدل از دیدگاههای مختلف نظری مورد بررسی قرار میگیرد تا مشخص شود آیا علاوه بر عملکرد تجربی مناسب، از پشتوانه تئوریک قابل قبولی نیز برخوردار است یا خیر. این تحلیل به درک عمیقتری از رفتار مدل کمک میکند و ارتباط میان ساختار مدل و نتایج حاصل را روشن میسازد.
تمرکز اصلی این تحلیل بر سه جنبه کلیدی شامل استحکام، تعمیمپذیری و پیچیدگی محاسباتی است. نتایج حاصل از این بررسیها نشان میدهند که روش ارائهشده تنها یک راهکار تجربی مبتنی بر آزمون و خطا نیست، بلکه از نظر نظری نیز قابل اتکا است 🧪. این تحلیلها رفتار مدل را در مواجهه با تغییرات داده، نمونههای جدید و محدودیتهای محاسباتی بهصورت شفاف مشخص میکنند و تصویری جامع از قابلیتهای روش پیشنهادی ارائه میدهند.
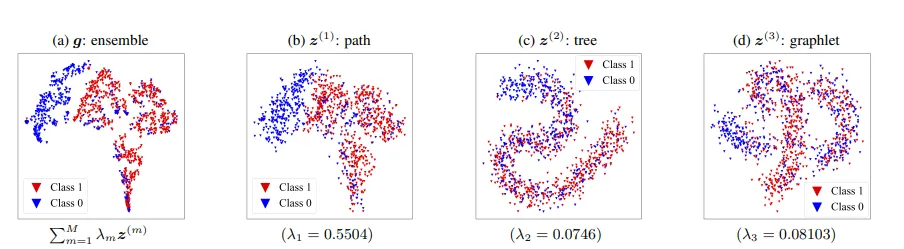
شکل ۲: نمایشهای تصویری t-SNE از تعبیههای کرنلی مختلف PXGL-EGK برای مجموعهداده PROTEINS.

شکل ۳: چارچوب روش پیشنهادی ما برای یادگیری نمایش گراف قابل توضیح مبتنی بر الگو با استفاده از شبکههای عصبی گرافی (PXGL-GNN).
۵.۱ تحلیل استحکام
استحکام مدل به میزان مقاومت آن در برابر اغتشاشهای کوچک در ساختار گراف یا ویژگیهای گرهها اشاره دارد 🛡️. در تحلیل ارائهشده، نشان داده میشود که تغییرات جزئی در گراف، تنها تأثیر محدودی بر نمایش نهایی گراف دارند و باعث ناپایداری شدید در خروجی مدل نمیشوند.
این ویژگی بهویژه در دادههای واقعی که اغلب با نویز، خطا یا عدم قطعیت همراه هستند اهمیت زیادی دارد 🔄. نتایج تحلیلی نشان میدهند که عواملی مانند درجه گرهها و عمق شبکه عصبی گراف نقش تعیینکنندهای در میزان استحکام مدل دارند و تنظیم مناسب آنها میتواند پایداری را افزایش دهد.
۵.۲ تحلیل تعمیمپذیری
تحلیل تعمیمپذیری به بررسی توانایی مدل در عملکرد مناسب بر روی دادههای دیدهنشده میپردازد 📈. در این چارچوب، از مفهوم پایداری یکنواخت برای ارائه کرانهایی بر خطای تعمیم استفاده میشود که ارتباط مستقیمی با ساختار مدل و فرآیند یادگیری دارند.
این کرانها نشان میدهند که با افزایش کیفیت دادههای آموزشی و انتخاب مناسب پارامترهای مدل، میتوان به تعمیمپذیری بالایی دست یافت 🌍. چنین تحلیلی اهمیت ویژهای برای کاربردهای عملی دارد، زیرا تضمین میکند که مدل در شرایط واقعی نیز قابل اعتماد باقی میماند.
۵.۳ پیچیدگی زمانی و مکانی
در این بخش، پیچیدگی زمانی و مکانی روشهای مختلف مورد بررسی قرار میگیرد ⏱️. روش مبتنی بر کرنل مجموعهای از نظر محاسباتی پرهزینه است، زیرا نیازمند محاسبه و ذخیره ماتریسهای کرنل بزرگ برای تمام گرافها در مجموعه داده میباشد.
در مقابل، روش مبتنی بر شبکههای عصبی گراف از مقیاسپذیری بهتری برخوردار است 💡. پیچیدگی زمانی این روش بهصورت خطی با اندازه دسته داده و تعداد یالها افزایش مییابد، که این ویژگی استفاده از آن را در مجموعهدادههای بزرگ و واقعی امکانپذیر میسازد.
۶. کارهای مرتبط
در این بخش، به پژوهشهای پیشین مرتبط با یادگیری گراف توضیحپذیر و کرنلهای گراف پرداخته شده است 📚. این مطالعات شامل روشهایی در سطح مدل، سطح نمونه و همچنین روشهای متمرکز بر یادگیری نمایش گراف هستند که هرکدام به جنبهای از توضیحپذیری توجه داشتهاند.
با وجود پیشرفتهای قابل توجه در این حوزه، بسیاری از این روشها تمرکز کافی بر توضیحپذیری «نمایش گراف» نداشتهاند ❗. مقاله حاضر با شناسایی این خلأ، رویکردی ارائه میدهد که بهطور خاص بر تفسیرپذیری نمایش گراف تمرکز دارد و جایگاه خود را در میان کارهای مرتبط مشخص میکند.
جدول ۱: آمار مجموعهدادهها
| نام | تعداد گرافها | تعداد کلاسها | میانگین تعداد گرهها | برچسب گره | ویژگی گره |
|---|---|---|---|---|---|
| MUTAG | 188 | 2 | 17.9 | بله | خیر |
| PROTEINS | 1113 | 2 | 39.1 | بله | بله |
| DD | 1178 | 2 | 284.32 | بله | خیر |
| NCI1 | 4110 | 2 | 29.9 | بله | خیر |
| COLLAB | 5000 | 3 | 74.49 | خیر | خیر |
| IMDB-B | 1000 | 2 | 19.8 | خیر | خیر |
| REDDIT-B | 2000 | 2 | 429.63 | خیر | خیر |
| REDDIT-M5K | 4999 | 5 | 508.52 | خیر | خیر |
۷. آزمایشها
برای ارزیابی عملی و تجربی چارچوب پیشنهادی، مجموعهای از آزمایشها بر روی دادههای واقعی گراف انجام شده است 🧪. این آزمایشها بهگونهای طراحی شدهاند که بتوانند هم توانایی مدل در یادگیری نمایشهای مؤثر و هم قابلیت توضیحپذیری آن را بهصورت همزمان بررسی کنند. در واقع، هدف تنها دستیابی به دقت بالاتر نبوده، بلکه سنجش این موضوع نیز مدنظر قرار گرفته است که آیا میتوان دلایل عملکرد مدل را نیز بهصورت ساختاری تحلیل کرد یا خیر.
در این چارچوب، نمایش ترکیبی حاصل از ادغام وزندار الگوهای مختلف با نمایشهای منفرد مبتنی بر یک الگو مقایسه شده است 📊. نتایج بهدستآمده نشان میدهد که ترکیب چند الگو در قالب یک نمایش یکپارچه، اطلاعات ساختاری متنوعتری را در بر میگیرد و در نتیجه عملکرد بهتری ایجاد میکند. علاوه بر این، وزنهای اختصاصیافته به هر الگو نهتنها در فرآیند یادگیری نقش دارند، بلکه بهعنوان شاخصی برای تحلیل ساختار دادهها نیز قابل استفاده هستند و تصویری روشن از اهمیت نسبی هر الگوی گرافی ارائه میدهند.
۷.۱ یادگیری نظارتشده
در سناریوی یادگیری نظارتشده، از برچسبهای موجود برای هر گراف بهمنظور آموزش مدل استفاده شده است 🎓. فرآیند آموزش بهگونهای انجام میشود که وزنهای مربوط به هر الگوی گرافی در جهت بهینهسازی تابع زیان تنظیم شوند. در نتیجه، مدل بهصورت خودکار یاد میگیرد که کدام ساختارهای گرافی برای پیشبینی برچسبها اهمیت بیشتری دارند.
تحلیل وزنهای نهایی نشان میدهد که برخی الگوها سهم پررنگتری در فرآیند طبقهبندی دارند و این موضوع بهصورت مستقیم قابل تفسیر است. نتایج طبقهبندی نیز بیانگر آن است که روش پیشنهادی در مقایسه با روشهای پایه عملکرد بهتری ارائه میدهد 🏆. نکته مهم این است که این بهبود عملکرد همراه با شفافیت ساختاری حاصل شده است؛ به این معنا که میتوان تصمیمات مدل را بر اساس سهم الگوهای خاص توضیح داد، نه صرفاً بر اساس یک نمایش غیرقابل تفسیر.
۷.۲ یادگیری بدون نظارت
در حالت یادگیری بدون نظارت، از واگرایی KL بهعنوان معیار یادگیری نمایشهای گراف استفاده شده است 🔄. در این سناریو، تمرکز بر استخراج ساختارهای ذاتی و روابط درونی میان گرافها بدون استفاده از برچسبهای از پیشتعریفشده است. مدل تلاش میکند نمایشهایی تولید کند که بتوانند توزیع دادهها را بهخوبی بازنمایی کنند.
نتایج حاصل از خوشهبندی نشان میدهد که نمایش ترکیبی همچنان نسبت به نمایشهای مبتنی بر الگوی منفرد عملکرد برتری دارد 📈. این برتری بیانگر آن است که ترکیب اطلاعات چندین الگوی گرافی میتواند ساختار پنهان دادهها را دقیقتر منعکس کند. علاوه بر این، وزنهای بهدستآمده در این حالت نیز قابل تحلیل هستند و نشان میدهند کدام الگوها در سازماندهی طبیعی دادهها نقش اساسیتری ایفا میکنند.
شکل ۴: نمایشهای تصویری t-SNE از نمایشهای الگوی PXGL-GNN (در حالت یادگیری نظارتشده) برای مجموعهداده PROTEINS.
جدول2: مقدار λ یادگرفتهشده برای PXGL-GNN (نظارتشده)
بیشترین مقدار بولد و دومین مقدار آبی مشخص شده است.
| الگو | MUTAG | PROTEINS | DD | NCI1 | COLLAB | IMDB-B | REDDIT-B | REDDIT-M5K |
|---|---|---|---|---|---|---|---|---|
| مسیرها | 0.095 ± 0.014 | 0.550 ± 0.070 | 0.093 ± 0.012 | 0.022 ± 0.002 | 0.587 ± 0.065 | 0.145 ± 0.018 | 0.131 ± 0.027 | 0.027 ± 0.003 |
| درختها | 0.046 ± 0.005 | 0.074 ± 0.009 | 0.054 ± 0.006 | 0.063 ± 0.003 | 0.105 ± 0.013 | 0.022 ± 0.003 | 0.055 ± 0.007 | 0.025 ± 0.003 |
| گرافلتها | 0.062 ± 0.008 | 0.081 ± 0.011 | 0.125 ± 0.015 | 0.101 ± 0.013 | 0.063 ± 0.008 | 0.084 ± 0.011 | 0.026 ± 0.003 | 0.054 ± 0.007 |
| چرخهها | 0.654 ± 0.085 | 0.099 ± 0.013 | 0.094 ± 0.012 | 0.176 ± 0.022 | 0.022 ± 0.003 | 0.123 ± 0.016 | 0.039 ± 0.005 | 0.037 ± 0.005 |
| کلیکها | 0.082 ± 0.011 | 0.098 ± 0.012 | 0.572 ± 0.073 | 0.574 ± 0.075 | 0.134 ± 0.017 | 0.453 ± 0.054 | 0.279 ± 0.069 | 0.256 ± 0.067 |
| چرخها | 0.026 ± 0.003 | 0.039 ± 0.005 | 0.051 ± 0.007 | 0.012 ± 0.002 | 0.068 ± 0.009 | 0.037 ± 0.004 | 0.036 ± 0.005 | 0.023 ± 0.003 |
| ستارهها | 0.035 ± 0.005 | 0.056 ± 0.007 | 0.011 ± 0.002 | 0.052 ± 0.007 | 0.021 ± 0.003 | 0.136 ± 0.017 | 0.447 ± 0.006 | 0.578 ± 0.033 |
جدول3: دقت (%) طبقهبندی گرافها
بهترین دقت با بولد و دومین دقت با
رنگ آبی مشخص شده است.
| روش | MUTAG | PROTEINS | DD | NCI1 | COLLAB | IMDB-B | REDDIT-B | REDDIT-M5K |
|---|---|---|---|---|---|---|---|---|
| GIN | 84.53 ± 2.38 | 73.38 ± 2.16 | 76.38 ± 1.58 | 73.36 ± 1.78 | 75.83 ± 1.29 | 72.52 ± 1.62 | 83.27 ± 1.30 | 52.48 ± 1.57 |
| DiffPool | 86.72 ± 1.95 | 76.07 ± 1.62 | 77.42 ± 2.14 | 75.42 ± 2.16 | 78.77 ± 1.36 | 73.55 ± 2.14 | 84.16 ± 1.28 | 51.39 ± 1.48 |
| DGCNN | 84.29 ± 1.16 | 75.53 ± 2.14 | 76.57 ± 1.09 | 74.81 ± 1.53 | 77.59 ± 2.24 | 72.19 ± 1.97 | 86.33 ± 2.29 | 53.18 ± 2.41 |
| GraphSAGE | 86.35 ± 1.31 | 74.21 ± 1.85 | 79.24 ± 2.25 | 77.93 ± 2.04 | 76.37 ± 2.11 | 73.86 ± 2.17 | 85.59 ± 1.92 | 51.65 ± 2.55 |
| SubGNN | 87.52 ± 2.37 | 76.38 ± 1.57 | 82.51 ± 1.67 | 82.58 ± 1.79 | 81.26 ± 1.53 | 71.58 ± 1.20 | 88.47 ± 1.83 | 53.27 ± 1.93 |
| SAN | 92.65 ± 1.53 | 75.62 ± 2.39 | 81.36 ± 2.10 | 83.07 ± 1.54 | 82.73 ± 1.92 | 75.27 ± 1.43 | 90.38 ± 1.54 | 55.49 ± 1.75 |
| SAGNN | 93.24 ± 2.51 | 75.61 ± 2.28 | 84.12 ± 1.73 | 81.29 ± 1.22 | 79.94 ± 1.83 | 74.53 ± 2.57 | 89.57 ± 2.13 | 54.11 ± 1.22 |
| ICL | 91.34 ± 2.19 | 75.44 ± 1.26 | 82.77 ± 1.42 | 83.45 ± 1.78 | 81.45 ± 1.21 | 73.29 ± 1.46 | 90.13 ± 1.40 | 56.21 ± 1.35 |
| S2GAE | 89.27 ± 1.53 | 76.47 ± 1.12 | 84.30 ± 1.77 | 82.37 ± 2.24 | 82.35 ± 2.34 | 75.77 ± 1.72 | 90.21 ± 1.52 | 54.53 ± 2.17 |
| PXGL-GNN | 94.87 ± 2.26 | 78.23 ± 2.46 | 86.54 ± 1.95 | 85.78 ± 2.07 | 83.96 ± 1.59 | 77.35 ± 2.32 | 91.84 ± 1.69 | 57.36 ± 2.14 |
۸. نتیجهگیری
در این مقاله، دو رویکرد مکمل برای یادگیری نمایش گراف قابل توضیح معرفی و بررسی شد 🎯. رویکرد نخست مبتنی بر کرنلهای مجموعهای گراف است که با شمارش و ترکیب وزندار الگوهای ساختاری، یک نمایش صریح و قابل تفسیر ارائه میدهد. رویکرد دوم از شبکههای عصبی گراف برای یادگیری نمایشهای غنیتر بهره میگیرد و از طریق تحلیل الگوهای نمونهبرداریشده، توضیحپذیری را در سطح نمایش حفظ میکند.
تحلیلهای نظری ارائهشده نشان میدهند که چارچوب پیشنهادی از نظر استحکام و تعمیمپذیری نیز دارای پشتوانه تحلیلی مناسب است 🧪. نتایج تجربی نیز تأیید میکنند که ترکیب وزندار الگوها نهتنها عملکرد مدل را بهبود میبخشد، بلکه امکان تفسیر ساختاری تصمیمات را فراهم میکند ✅. در مجموع، این چارچوب گامی مؤثر در جهت توسعه روشهای یادگیری گراف شفاف، قابل اعتماد و ساختارمحور به شمار میرود 🌱.