🧠 ارزیابی اقتصادی مدلهای هوش مصنوعی با GDPval
معیاری نوین برای سنجش ارزش واقعی هوش مصنوعی در اقتصاد جهانی
مقدمه: چرا ارزیابی اقتصادی مدلهای هوش مصنوعی ضروری است؟
هوش مصنوعی در دههی اخیر از مرحلهی آزمایشگاهی به بطن اقتصاد جهانی رسیده است. از تولید محتوا تا تحلیل مالی، از طراحی صنعتی تا پزشکی، هوش مصنوعی در حال بازتعریف ماهیت کار انسانی است.
اما پرسش اصلی اینجاست: چگونه میتوان ارزش واقعی عملکرد مدلهای هوش مصنوعی را در جهان واقعی سنجید؟
تا پیش از سال ۲۰۲۵، بیشتر ارزیابیها صرفاً به آزمونهای تحلیلی و شناختی محدود میشدند؛ مانند MMLU، GPQA یا BIG-Bench که توان مدلها را در حل سؤالات دانشگاهی میسنجیدند. اما هیچیک از اینها نشان نمیدادند که یک مدل واقعاً در کار روزمرهی اقتصادی چقدر کارا، دقیق و ارزشآفرین است.
اینجاست که GDPval بهعنوان نخستین معیار ارزیابی عملکرد مدلهای هوش مصنوعی بر اساس وظایف اقتصادی واقعی وارد میدان میشود.
آشنایی با GDPval
تعریف و فلسفهی شکلگیری GDPval
GDPval مخفف “Gross Domestic Product Value Benchmark” است؛ چارچوبی که توسط تیم OpenAI در سال ۲۰۲۵ معرفی شد تا عملکرد مدلهای هوش مصنوعی را در انجام وظایف واقعی و اقتصادی بسنجد.
هدف GDPval این است که نشان دهد مدلها تا چه اندازه میتوانند کارهایی را انجام دهند که در دنیای واقعی برای انسانها ارزش اقتصادی دارند — نه فقط پاسخ به پرسشهای انتزاعی.
به بیان ساده، اگر یک کار توسط یک متخصص انسانی در بازار واقعی انجام میشود، GDPval میسنجد آیا مدل هوش مصنوعی میتواند همان کار را با کیفیت مشابه، هزینه کمتر، و سرعت بیشتر انجام دهد یا نه.
دامنه پوشش GDPval
GDPval شامل وظایف واقعی از ۹ بخش اصلی اقتصاد آمریکا است که مجموعاً بیش از ۷۰٪ از تولید ناخالص داخلی (GDP) را تشکیل میدهند. این بخشها شامل:
خدمات مالی و بیمه
فناوری اطلاعات و ارتباطات
تولید و مهندسی
بهداشت و درمان
آموزش و دولت
تجارت عمدهفروشی و خردهفروشی
رسانه و ارتباطات
املاک و خدمات حرفهای
در مجموع، GDPval ۴۴ شغل تخصصی را در این حوزهها پوشش داده است؛ از تحلیلگر مالی و مهندس نرمافزار گرفته تا وکیل، طراح، پزشک و مدیر بازاریابی.

شیوهی ساخت و ارزیابی وظایف در GDPval
ساختار وظایف (Tasks)
در GDPval هر وظیفه شامل دو بخش است:
درخواست (Prompt) — که مانند دستورالعمل واقعی کاری طراحی میشود،
تحویلدادنی (Deliverable) — نتیجهی نهایی که مدل باید تولید کند (مثلاً گزارش، فایل اکسل، ارائه، تصویر یا تحلیل داده).
این وظایف توسط کارشناسان با میانگین ۱۴ سال سابقه کاری واقعی طراحی شدهاند و بازتاب دقیقی از کار روزمره در شرکتها و سازمانهای واقعی هستند.
کنترل کیفیت چندمرحلهای
برای حفظ دقت و واقعگرایی، هر وظیفه در GDPval پنج مرحلهی بازبینی انسانی و خودکار را میگذراند:
بررسی اتوماتیک با مدلهای زبانی (Model-in-the-loop QA)
بازبینی اولیه توسط متخصص عمومی
بازبینی تخصصی شغلی
اصلاح بر اساس بازخورد کارشناسان
تأیید نهایی توسط داوران ارشد
نتیجهی این فرایند مجموعهای از بیش از ۱۳۲۰ وظیفه واقعی و پیچیده است که انجام آنها برای انسان متخصص حدود ۷ ساعت زمان نیاز دارد.
روش ارزیابی مدلها
مقایسهی انسان و مدل در میدان واقعی
در این پروژه، عملکرد مدلهای مختلف از جمله GPT-5، Claude Opus، Gemini 2.5 Pro و Grok-4 در مقابل کارشناسان انسانی قرار گرفت.
کارشناسان شغلی (مثل پزشکان، مهندسان یا تحلیلگران مالی) خروجی مدلها را در قالب مقایسهی دوتایی (Pairwise Grading) ارزیابی کردند.
بهعنوان نمونه، به داور انسانی دو پاسخ بینام (یکی از انسان و یکی از مدل) داده میشد تا تعیین کند کدام خروجی بهتر، دقیقتر و حرفهایتر است.
معیار اصلی: نرخ پیروزی (Win Rate)
در GDPval، برخلاف نمرههای سنتی، معیار اصلی نرخ پیروزی مدل است؛ یعنی درصد دفعاتی که خروجی مدل در مقایسه با انسان بهتر یا برابر ارزیابی شده است.
در نتایج اولیه:
Claude Opus 4.1 بیشترین امتیاز زیباییشناسی را کسب کرد (طراحی و ارائه فایلهای زیبا).
GPT-5 بیشترین دقت در پیروی از دستورالعملها و صحت محاسبات را داشت.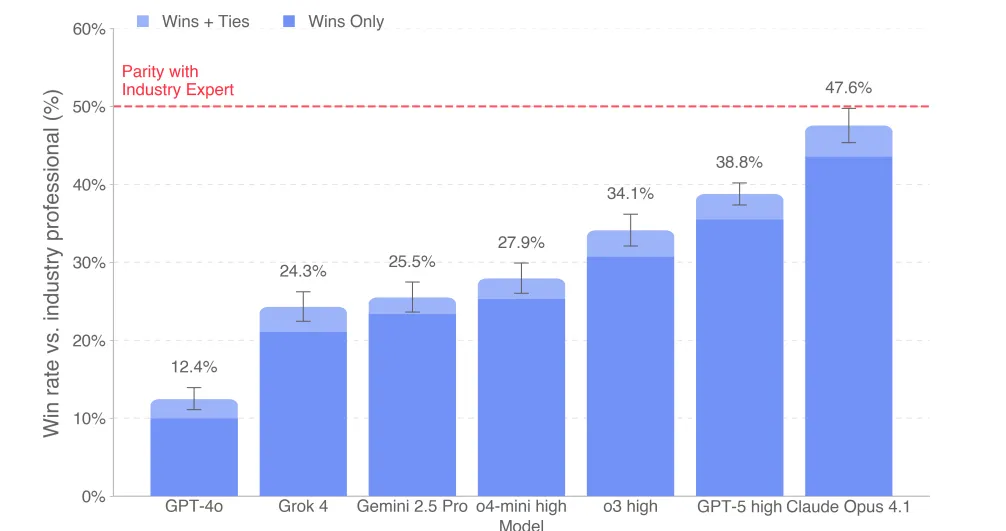 بهطور میانگین، مدلهای پیشرفته در بیش از ۴۷٪ موارد عملکردی برابر یا بهتر از متخصصان انسانی نشان دادند — جهشی تاریخی در مسیر هوش مصنوعی کاربردی.
بهطور میانگین، مدلهای پیشرفته در بیش از ۴۷٪ موارد عملکردی برابر یا بهتر از متخصصان انسانی نشان دادند — جهشی تاریخی در مسیر هوش مصنوعی کاربردی.
هزینه، سرعت و بهرهوری
مدل در برابر انسان؛ مقایسه اقتصادی
یکی از شاخصترین یافتههای GDPval، محاسبهی صرفهجویی در زمان و هزینه بود.
در سناریوی «استفاده از مدل با نظارت انسانی»، مدلها توانستند:
تا ۱.۶ برابر سریعتر از انسان وظایف را تکمیل کنند،
و در عین حال تا ۵۰٪ صرفهجویی اقتصادی نسبت به انجام مستقل کار توسط انسان ایجاد نمایند.
بهویژه GPT-5 در ترکیب با بازبینی انسانی، بهترین نسبت سرعت-کیفیت را داشت.
مفهوم «Try n times and fix»
GDPval سناریوی واقعبینانهای را شبیهسازی کرد:
کارشناس چند بار از مدل خروجی میگیرد (n بار)، هر بار آن را بررسی میکند، و در صورت نارضایتی، خودش اصلاح نهایی را انجام میدهد.
نتیجه نشان داد که در این مدل هیبریدی، بهرهوری نهایی تا ۴۰٪ افزایش و هزینهی نیروی انسانی بهشدت کاهش مییابد.
تحلیل نقاط قوت و ضعف مدلها
قوتها
GPT-5: دقت بالا در پیروی از دستورالعمل و انجام محاسبات
Claude Opus: برتری در زیبایی و انسجام فایلهای بصری (PDF، PPT)
Gemini: سرعت و تنوع پاسخ
Grok: خلاقیت و تولید ایدههای غیرمتعارف
ضعفها
بیتوجهی به قالب و فرمت در برخی مدلها
خطاهای محاسباتی در وظایف پیچیده
عدم درک کامل زمینههای چندمرحلهای یا چندمنبعی
گاهی تولید محتوای غیرقابلاستفاده یا ناقص
با این حال، بیشتر شکستهای GPT-5 در ردهی «قابلقبول اما ضعیفتر از انسان» بودهاند، نه فاجعهآمیز.
نقش «استدلال عمیق» در بهبود عملکرد
آزمایش تلاش استدلالی (Reasoning Effort)
OpenAI در GDPval آزمایش کرد که اگر به مدل فرصت و زمان بیشتری برای تفکر داده شود، آیا کیفیت خروجی افزایش مییابد؟
نتیجه مثبت بود:
افزایش تلاش استدلالی باعث رشد قابلپیشبینی در کیفیت و تطابق با خواستهها شد.
همچنین استفاده از Prompt-Tuning و Scaffolding (ساختاردهی هوشمندانهی درخواستها) توانست خطاهای فرمت و نگارش را تا بیش از ۵۰٪ کاهش دهد.
نسخهی طلایی (Gold Subset) و متنباز شدن GDPval
دسترسی عمومی برای پژوهشگران
OpenAI نسخهی متنباز GDPval را با ۲۲۰ وظیفهی واقعی در دسترس پژوهشگران قرار داده است.
این مجموعه شامل درخواستها، فایلهای مرجع و سامانهی ارزیابی خودکار است که از طریق وبسایت evals.openai.com قابل استفاده است.
هدف از این کار، ایجاد بستری برای پایش پیشرفت مدلها در دنیای واقعی و مقایسهی عادلانهی مدلهای مختلف است.
محدودیتهای GDPval
چالشهای فعلی
۱. تمرکز بر مشاغل دیجیتال؛ کارهای فیزیکی فعلاً پوشش داده نشدهاند.
۲. وظایف در حالت تکمرحلهای طراحی شدهاند، نه تعاملی و چندنفره.
۳. ارزیابی خودکار هنوز با دقت انسانی برابری ندارد.
۴. اجرای ارزیابی پرهزینه و زمانبر است، چون نیازمند متخصصان واقعی است.
با این حال، تیم پژوهش وعده داده است که در نسخههای آینده، GDPval شامل وظایف تعاملی، بلندمدت و بینرشتهای نیز خواهد شد.
تأثیر GDPval بر آینده بازار کار
از جایگزینی تا همکاری انسان و ماشین
نتایج GDPval نشان میدهد که مدلهای پیشرفته مانند GPT-5 میتوانند در بسیاری از وظایف تخصصی، همسطح یا حتی بهتر از کارشناسان انسانی عمل کنند.
اما پیام این پروژه «جایگزینی انسان» نیست، بلکه افزایش بهرهوری با همکاری انسان و مدل است.
مدلها میتوانند بخشی از کار را انجام دهند و انسانها با نظارت و خلاقیت خود کیفیت نهایی را تضمین کنند — چیزی که به آن Hybrid Intelligence گفته میشود.
اقتصاد هوش مصنوعی و آینده ارزیابیها
گذار از معیارهای آکادمیک به ارزش اقتصادی
GDPval نخستین گام در گذار از بنچمارکهای آزمایشگاهی به ارزیابیهای اقتصادی است.
در آینده، ارزش مدلها نه با نمرهی آزمونهای مصنوعی، بلکه با میزان ارزش واقعی تولیدشده در اقتصاد سنجیده خواهد شد.
این تحول به سیاستگذاران، شرکتها و پژوهشگران کمک میکند تا تصمیم بگیرند کجا سرمایهگذاری کنند و کدام مدل واقعاً ارزش اقتصادی ایجاد میکند.
نتیجهگیری
GDPval تنها یک بنچمارک نیست؛ بلکه تلاشی است برای درک علمی و اقتصادی از توان واقعی هوش مصنوعی در دنیای کار.
با ترکیب تخصص انسانی و دقت ماشینی، میتوان به مرحلهای رسید که مدلهای هوش مصنوعی نه فقط ابزار، بلکه شریک فکری و اقتصادی انسان باشند.
از این پس، پرسش اصلی دیگر این نیست که “AI چقدر باهوش است”، بلکه این است که “AI چقدر برای اقتصاد ارزش خلق میکند؟”
✅ خلاصه نهایی:
GDPval معیاری برای سنجش اقتصادی عملکرد مدلهاست.
۴۴ شغل، ۹ بخش اقتصادی و ۱۳۲۰ وظیفه واقعی را پوشش میدهد.
مدلهای نسل جدید (مثل GPT-5) در نیمی از وظایف عملکردی همتراز با متخصصان انسانی دارند.
آیندهی هوش مصنوعی در ترکیب هوشمند انسان + مدل است، نه جایگزینی یکی با دیگری.



