19 خطر حریم خصوصی در هوش مصنوعی که باید بدانید
🔐 حریم خصوصی در عصر هوش مصنوعی؛ طبقهبندی علمی خطرات دادهها ⭐ مقدمه با گسترش سریع هوش مصنوعی، حجم دادههای حساس در سیستمها به شکلی بیسابقه رشد کرده است. این تحول همراه با فرصتهای بزرگ، چالشهای جدی امنیتی و حریم خصوصی نیز ایجاد میکند. طبق مطالعات ارائهشده، سیستمهای هوش مصنوعی با ویژگیهایی چون یادگیری خودکار، […]
 مقالات
مقالات
🔐 حریم خصوصی در عصر هوش مصنوعی؛ طبقهبندی علمی خطرات دادهها
⭐ مقدمه
با گسترش سریع هوش مصنوعی، حجم دادههای حساس در سیستمها به شکلی بیسابقه رشد کرده است. این تحول همراه با فرصتهای بزرگ، چالشهای جدی امنیتی و حریم خصوصی نیز ایجاد میکند. طبق مطالعات ارائهشده، سیستمهای هوش مصنوعی با ویژگیهایی چون یادگیری خودکار، تصمیمگیری غیرشفاف و استخراج الگوهای پنهان، سطحی از ریسک را ایجاد میکنند که در چارچوبهای سنتی مدیریت امنیت دیده نمیشود. 📊 این موضوع سبب شده بسیاری از دادهها—even ناشناسسازیشده—قابل بازیابی و استنتاج مجدد باشند.
همزمان، پژوهشها نشان میدهند که در کنار پیشرفت مدلهای مولد و معماریهای عاملمحور، تهدیدات تازهای ایجاد میشوند که با روشهای کلاسیک حفاظت داده قابل مدیریت نیستند. این مقاله بر اساس یک مرور نظاممند ۴۵ مطالعه علمی، طبقهبندی جامعی از ۱۹ ریسک اصلی حریم خصوصی در چهار دسته ساختاری ارائه میدهد. این چارچوب علمی، راهنمایی کاربردی برای پژوهشگران و متخصصانی است که میخواهند پیامدهای واقعی و پیچیده پردازش داده در سیستمهای هوش مصنوعی را درک و مدیریت کنند. 🔍
📚 پسزمینه علمی و مرور ادبیات
🔄 تکامل نگرانیها درباره حریم خصوصی در هوش مصنوعی
در آغاز، نگرانیهای حوزه حریم خصوصی بیشتر بر جمعآوری و ذخیرهسازی دادهها متمرکز بود؛ اما با هوشمندتر شدن سیستمها، این نگرانیها به کل چرخه حیات داده گسترش یافت. تحقیقات نشان میدهد هوش مصنوعی قادر است از دادههای ظاهراً غیرحساس، اطلاعات حساس جدید استخراج کند. 🧩 این یعنی حتی دادههایی که تصور میکنیم امن هستند، میتوانند در کنار دادههای دیگر هویت افراد را آشکار کنند.
پژوهشها همچنین نشان میدهند فناوریهای نو مانند مدلهای مولد، توانایی ساخت محتوای مصنوعی دارند که گاهی ناخواسته اطلاعات خصوصی را بازسازی و تقلید میکند. حتی محیطهای یادگیری فدرال—که با هدف افزایش محرمانگی طراحی شدهاند—در برابر حملات استنتاجی آسیبپذیر هستند. این یافتهها ثابت میکند که نگرانیهای حریم خصوصی، نهتنها کاهش نیافته بلکه با پیچیدگی بیشتری همراه شده است. ⚠️
🧩 طبقهبندیها و چارچوبهای موجود در ادبیات
چندین پژوهش تلاش کردهاند خطرات هوش مصنوعی را دستهبندی کنند، اما اغلب این کار را با تمرکز بر تهدیدات کلی انجام دادهاند و کمتر به محتوای دقیق حریم خصوصی پرداختهاند. اگرچه برخی از چارچوبها جنبههای امنیتی و اعتمادپذیری را بررسی میکنند، اما کمتر به ماهیت اختصاصی تهدیدات حریم خصوصی ناشی از مدلهای پیشرفته پرداخته شده است. 🌐
تحقیقات نشان میدهد چارچوبهای موجود بیشتر فنی هستند و ابعاد انسانی، سازمانی و رفتاری را نادیده میگیرند. با توجه به اینکه بسیاری از نقضهای حریم خصوصی ناشی از خطای انسانی است، این خلأ علمی اهمیت بالایی دارد. همین شکاف پژوهشی، ضرورت ایجاد یک طبقهبندی نظاممند ویژه خطرات دادهای در سیستمهای هوش مصنوعی را روشن میکند. 🧠
🔬 روش تحقیق
🧭 انتخاب مطالعات و ارزیابی کیفیت
این پژوهش با پرسش اصلی «خطرات کلیدی حریم خصوصی در سیستمهای هوش مصنوعی چیست؟» طراحی و اجرا شده است. جستجو در هفت پایگاه معتبر علمی و صنعتی با روش PRISMA انجام و ۶۳۳ مطالعه اولیه شناسایی شد که پس از غربالگریهای متعدد، ۴۵ مطالعه باکیفیت به عنوان داده نهایی انتخاب شدند. این فرآیند شامل بررسی عنوان، چکیده، متن کامل و ارزیابی کیفیت روششناختی بود. 🔍
معیارهای ورود و خروج مطالعات نیز با دقت مشخص شدهاند تا فقط پژوهشهایی که واقعاً بر حریم خصوصی در هوش مصنوعی تمرکز دارند باقی بمانند. این ارزیابی سنگین، اطمینان میدهد که نتایج نهایی مبتنی بر معتبرترین و دقیقترین منابع علمی سالهای ۲۰۲۰ تا ۲۰۲۵ هستند. 📘

شکل1:فرآیند پنج مرحلهای انتخاب مطالعات با استفاده از روش PRISMA (2020) برای شناسایی، ترکیب و طبقهبندی خطرات حریم خصوصی در سیستمهای هوش مصنوعی.
| معیارهای ورود | معیارهای خروج |
|---|---|
| مطالعاتی که بهطور خاص به خطرات حریم خصوصی در سیستمهای هوش مصنوعی پرداختهاند | مطالعاتی که به هوش مصنوعی یا خطرات حریم خصوصی مرتبط نیستند |
| مقالات منتشرشده به زبان انگلیسی از ژانویه 2020 تا جولای 2025 | مقالات غیرپژوهشی یا مقالاتی که دسترسی به متن کامل آنها وجود ندارد |
| مقالات داوریشده، مقالات کنفرانسی، گزارشهای فنی، مقالات سفید، و انتشارات موسسات | پژوهشهایی که از روششناسی مبهم یا نتایج تفصیلی ضعیف برخوردار هستند |
| مطالعاتی که بهطور خاص به خطرات حریم خصوصی، خطرات داده و فناوریهای هوش مصنوعی پرداختهاند | پژوهشهایی که در ارتباط با حفظ حریم خصوصی در سیستمهای هوش مصنوعی نیستند |
جدول1: معیارهای انتخاب و رد مطالعات در فرآیند مرور نظاممند بررسی خطرات حریم خصوصی در سیستمهای هوش مصنوعی
🧱 توسعه و اعتبارسنجی طبقهبندی
پس از انتخاب مطالعات، استخراج ۱۹ ریسک کلیدی با استفاده از کدگذاری تماتیک انجام شد. این ریسکها سپس به چهار دسته بزرگ تقسیم شدند: ریسکهای سطح داده، سطح مدل، سطح زیرساخت و تهدیدات داخلی. هر مرحله با بازبینی مداوم توسط پژوهشگران ارشد همراه بوده تا با اجماع علمی تقویت شود. 🧪
در پایان، واژگان و ساختار طبقهبندی با استانداردهای ادبیات حریم خصوصی تطبیق داده شد تا خوانایی و انسجام را افزایش دهد. این رویکرد مرحلهبهمرحله، چارچوبی دقیق و قابلاعتماد برای درک ریسکهای حریم خصوصی هوش مصنوعی فراهم کرده است. ✔️
| مرحله | نام مرحله | توضیحات |
|---|---|---|
| ۱ | کدگذاری تماتیک ریسکها | پس از مرور کامل متون، کدگذاری استقرایی روی ۴۵ مطالعه انجام شد تا ریسکهای حریم خصوصی استخراج شوند. این ریسکها بر اساس الگوهای تکرارشونده در مفاهیم، اصطلاحات و حوزههای تمرکز گروهبندی شدند. نتیجه این مرحله شناسایی ۱۹ ریسک مجزا بود. |
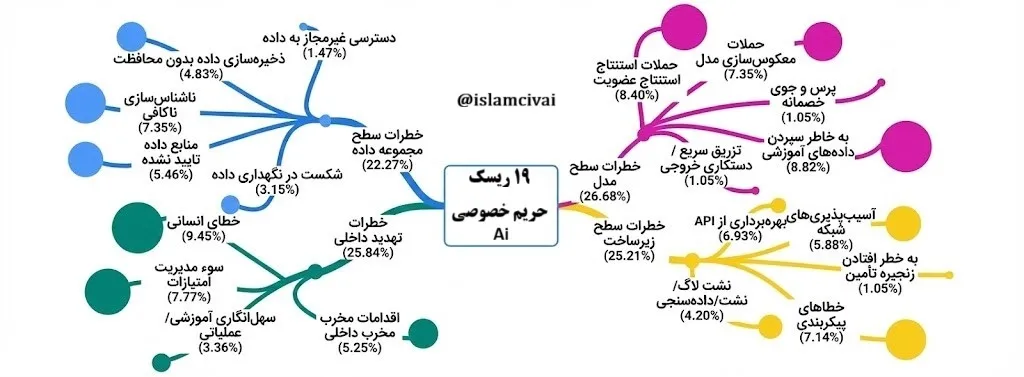
| ۲ | دستهبندی تدریجی در شاخههای تماتیک | ریسکهای شناساییشده در چهار دسته اصلی سازماندهی شدند. این دستهبندی بر پایه دانش حوزه و الگوهای رایج در ادبیات مربوط به هوش مصنوعی و حریم خصوصی شکل گرفت. برای تفکیک بصری دستهها، رنگبندی شاخهها در تصویر مربوط به طبقهبندی اعمال شد (Figure 2). |
| ۳ | کاهش سوگیری و اعتبارسنجی از طریق بازبینی | برای افزایش شفافیت و انسجام، طبقهبندی در جلسات دوهفتهای با پژوهشگران ارشد بازبینی شد. هر ریسک و دستهبندی آن بررسی شد تا ارتباط آن با معیارهای ورود تأیید شود. اصلاحات لازم با اجماع انجام گرفت تا انسجام مفهومی حفظ شود. |
| ۴ | تثبیت و یکپارچگی واژگان | در پایان، واژگان مورد استفاده در طبقهبندی با ادبیات علمی موجود هماهنگ شد. تعریف ریسکها و نام دستهها برای وضوح بیشتر اصلاح شد تا با زبان رایج در پژوهشهای امنیت و حریم خصوصی تطابق کامل داشته باشد. |
جدول 2: مراحل کلیدی توسعه و اعتبارسنجی طبقهبندی ریسکهای حریم خصوصی در سیستمهای هوش مصنوعی
📊 نتایج و یافتهها
🗂️ نمای کلی طبقهبندی
تحلیل ۴۵ مطالعه منجر به شناسایی ۱۹ ریسک و توزیع تقریباً متوازن آنها شد:
- سطح مدل: ۲۶.۶۷٪
- تهدیدات داخلی: ۲۵.۸۷٪
- زیرساخت: ۲۵.۲۰٪
- سطح داده: ۲۲.۲۶٪
19 ریسک شناسایی شده
🧩 ریسکهای سطح داده (Dataset-Level)
ریسکهایی مانند «عدم ناشناسسازی کافی»، «منابع داده تأییدنشده» و «ذخیرهسازی ناامن» بخشی از چالشهایی هستند که مطالعات متعدد بر آنها تأکید کردهاند. برای مثال مشخص شده که بسیاری از دادههای بهظاهر ناشناس، قابل بازشناسایی مجدد هستند. همین موضوع، مشکلات مهمی برای استفاده از داده در مدلهای هوش مصنوعی ایجاد میکند. 📦
همچنین ذخیرهسازی دادهها بدون کنترلهای امنیتی کافی باعث دستکاری یا افشای اطلاعات میشود. وجود دادههای نامعتبر یا ناشناسسازی ناقص میتواند نهتنها حریم خصوصی افراد را نقض کند بلکه کل خروجی مدل را با خطا مواجه سازد. 🛑
- دسترسی غیرمجاز به دادهها – دسترسی افراد یا سیستمها بدون مجوز مناسب
- ذخیرهسازی دادهها بدون حفاظت – فقدان رمزگذاری و کنترلهای دسترسی
- منابع داده تأییدنشده – استفاده از دادههای نامعتبر یا غیرقانونی
- شکست در نگهداری دادهها (Data Retention Failures) – ذخیره طولانی دادهها بیش از حد لازم
- ناشناسسازی ناکافی (Insufficient Anonymisation) – اطلاعات هنوز قابل شناسایی هستند
🧠 ریسکهای سطح مدل(Model-Level)
مدلها میتوانند دادههای حساس را «به خاطر بسپارند» و حتی بخشهایی از آن را بازتولید کنند. تحقیقات نشان داده مدلهای بزرگ حتی اطلاعاتی که فقط یکبار در داده آموزشی آمدهاند را نیز بازگو میکنند. این پدیده یکی از جدیترین تهدیدات حریم خصوصی در مدلهای یادگیری ماشینی است. 🤖
از سوی دیگر حملاتی مانند استنتاج عضویت و معکوسسازی مدل قادرند حضور افراد در داده آموزشی را افشا کنند یا حتی تصویر چهره آنها را از مدل بازسازی نمایند. این نوع آسیبپذیریها ذاتیِ ساختار مدلها هستند و با روشهای سنتی حریم خصوصی قابل حل نیستند. 🧨
- حملات استنتاج عضویت (Membership Inference Attacks) – تعیین اینکه دادهای در آموزش مدل استفاده شده است
- حملات معکوسسازی مدل (Model Inversion Attacks) – بازسازی دادههای حساس از خروجی مدل
- حافظهسپاری دادهها در مدل (Training Data Memorisation) – مدلها اطلاعات حساس را به خاطر میسپارند
- تزریق دستور/دستکاری خروجی (Prompt Injection / Output Manipulation) – ورودیهای مخرب برای افشای اطلاعات
- استعلام خصمانه (Adversarial Querying) – استخراج سیستماتیک دادههای خصوصی با استفاده از رفتار مدل
🖥️ ریسکهای زیرساختی (Infrastructure-Level)
پژوهشها نشان میدهند اشتباهات پیکربندی، APIهای ناامن و آسیبپذیری شبکه از رایجترین مشکلات زیرساختی هستند. برای مثال بسیاری از سازمانها تنظیمات امنیتی اولیه را هنگام استقرار مدلها به درستی انجام نمیدهند و همین موضوع سطح حمله را گسترده میکند. 🌐
APIهای غیرایمن نیز به مهاجمان اجازه میدهند داده یا عملکردهای حساس مدل را استخراج کنند. بررسیهای متعدد ثابت کردهاند که پیکربندی نامناسب سرویسهای ابری و نادیده گرفتن تنظیمات پیشفرض یکی از مهمترین عوامل تهدید در این بخش است. 🔓
- سوءاستفاده از API (API Exploitation) – استفاده غیرمجاز از نقاط دسترسی سیستم
- آسیبپذیری شبکه (Network Vulnerabilities) – ضعف شبکهها که میتواند منجر به دسترسی شود
- نفوذ زنجیره تأمین (Supply Chain Compromise) – وارد شدن اجزای مخرب از منابع خارجی
- خطاهای پیکربندی (Configuration Errors) – تنظیمات نادرست سیستمهای AI
- افشای اطلاعات لاگ/تلهمتری (Logging/Telemetry Leaks) – ثبت اطلاعات حساس بدون محافظت
🧑💼 تهدیدات داخلی (Insider Threats)
در این گروه، خطای انسانی بزرگترین عامل تهدید است. اشتباهاتی مثل اشتراکگذاری نادرست، دسترسیدهی بیرویه، یا مدیریت نادرست دادهها باعث بیشترین موارد نقض حریم خصوصی میشوند. 🧯
علاوه بر خطای انسانی، سوءاستفاده کارکنان یا فقدان آموزش کافی نیز نقش پررنگی دارد. پژوهشها نشان میدهند نبود کنترل دسترسی دقیق و عدم آگاهی کارکنان از اصول حریم خصوصی، عامل بسیاری از رخنههای امنیتی در سیستمهای هوش مصنوعی است. 🔑
- اقدامات مخرب کارکنان (Malicious Insider Actions) – سوءاستفاده عمدی کارکنان داخلی
- خطای انسانی (Human Error) – اشتباهات ناخواسته افراد
- مدیریت نادرست دسترسیها (Privilege Mismanagement) – اعطای دسترسی بیش از حد یا نامناسب
- بیتوجهی آموزشی/عملیاتی (Training/Operational Negligence) – کمبود آموزش یا رعایت نکردن سیاستها
– بیشترین ریسک پرتکرار: خطای انسانی (۹.۴۵٪) و حافظهسپاری دادهها (۸.۸۲٪)
– این ریسکها ذاتی سیستمهای AI هستند و برخی با روشهای سنتی حریم خصوصی قابل کنترل نیستند.
🧵 بحث
نتایج نشان میدهد که ریسکهای سطح مدل از سایر ابعاد پررنگترند و نیاز به کنترلهای ویژه دارند. همچنین یافته مهم این است که عامل انسانی در بسیاری از رخدادهای نقض حریم خصوصی نقش کلیدی دارد؛ بنابراین توجه صرف به ابعاد فنی کافی نیست. 🔍
علاوه بر این، پژوهشها بیان میکنند که سازمانهایی با چارچوبهای حاکمیتی بالغتر در حوزه هوش مصنوعی، میزان رخدادهای کمتری را تجربه کردهاند. این موضوع اهمیت معماریهای نظارتی و چارچوبهای ارزیابی را بیش از پیش آشکار میسازد. 🧭
🏁 نتیجهگیری
این مطالعه با تحلیل ۴۵ پژوهش معتبر، طبقهبندی جامعی از ۱۹ ریسک حریم خصوصی در چهار دسته ارائه میدهد. نتایج نشان میدهد که حفاظت از حریم خصوصی در عصر هوش مصنوعی نیازمند رویکردی چندرشتهای و جامع است؛ ترکیبی از کنترلهای فنی، سازمانی و رفتاری. 🔐
اکوسیستم فعلی هوش مصنوعی، بدون ابزارهای تخصصی ارزیابی ریسک نمیتواند پاسخگوی تهدیدات پیچیده امروز باشد. این طبقهبندی پایهای علمی و قابل اتکا برای توسعه راهکارهای بهتر، استانداردهای دقیقتر و سیستمهای قابلاعتمادتر در آینده فراهم میکند. 🚀
مقاله قبلی هوش مصنوعی در محیطهای نامطمئن هم دقیق شد!👉