🏛️ مدلسازی هستیشناسی دامنه در آرشیو دیجیتال مرکز اسناد انقلاب اسلامی ایران
1. مقدمه: چالش سازماندهی دانش در آرشیوهای دیجیتال 🌐
سازماندهی اطلاعات و دانش، ستون اصلی هر نظام بازیابی اطلاعات کارآمد است که پرسوجوی کاربران را به مدارک مرتبط هدایت میکند. در عصر دیجیتال، کتابخانهها و آرشیوها با حجم عظیمی از دادهها مواجهاند که مدیریت آنها نیازمند استانداردهای نوین توصیف و کدگذاری برای تعاملپذیری بهتر است.آرشیوهای تاریخی بزرگ، مانند مرکز اسناد انقلاب اسلامی، با چالشهای پیچیدهای در سازماندهی حجم بالایی از اطلاعات دیجیتال دستوپنجه نرم میکنند. این مراکز برای بهبود دسترسی معنایی به موجودیتهای کلیدی، ناگزیر به استفاده از رویکردهای نوآورانه مانند هستیشناسی دامنه و گرافهای دانش هستند.
2. ناکارآمدی نظامهای سنتی بازیابی اطلاعات ⚠️
🔹 2.1. محدودیت جستجوی متنی و فرادادهای
نظامهای بازیابی اطلاعات سنتی در آرشیوها عمدتاً بر پایه تطبیق ساده کلمات کلیدی و فرادادههای توصیفی اولیه بنا شدهاند. این سیستمها فاقد توانایی درک زمینههای معنایی هستند و نمیتوانند تفاوتهای ظریف بین مفاهیم مشابه یا مترادف را در میان انبوه اسناد تشخیص دهند. در واقع، این روشها تنها به لایههای سطحی اطلاعات دسترسی دارند و از تحلیل عمق محتوایی باز میمانند.
عدم درک روابط میان مفاهیم باعث میشود که نتایج جستجو اغلب شامل موارد غیرمرتبط باشد یا بسیاری از اسناد کلیدی به دلیل عدم تطبیق دقیق واژگانی، بازیابی نشوند. این محدودیت در نظامهای سنتی، شکاف بزرگی میان «نیاز اطلاعاتی واقعی پژوهشگر» و «نتایج ارائه شده توسط ماشین» ایجاد میکند. در نتیجه، سازماندهی دانش در این مدلها از پویایی لازم برای پاسخگویی به پرسشهای پیچیده علمی برخوردار نیست.
🔹 2.2. پیامدهای این محدودیت در آرشیو مرکز اسناد
مرکز اسناد انقلاب اسلامی با دارا بودن بیش از ۴.۵ میلیون برگ سند و هزاران ساعت تاریخ شفاهی، با چالش جدی در بازیابی دقیق مواجه است. محدودیتهای سنتی باعث میشود که بسیاری از «موجودیتهای پنهان» در دل خاطرات و نامهها، هرگز در نتایج جستجو ظاهر نشوند. این موضوع باعث میشود که پژوهشگران تاریخ معاصر نتوانند به تمامی ابعاد یک واقعه یا نقش دقیق یک شخصیت تاریخی دست یابند.
کاهش دقت در بازیابی اطلاعات در چنین حجم عظیمی از داده، منجر به صرف زمان طولانی و هزینههای گزاف برای استخراج دانش میشود. وقتی سیستم نتواند پیوند میان یک رویداد سیاسی و اشخاص مرتبط با آن را به صورت خودکار شناسایی کند، دسترسی جامع به تاریخ دشوار میگردد. این پیامدها ضرورت عبور از بازیابی سنتی و حرکت به سمت مدلهای معنایی و گراف دانش را در این مرکز دوچندان کرده است.
3. هستیشناسی دامنه؛ رویکردی نوین در سازماندهی دانش 💡
🔹 3.1. تعریف هستیشناسی دامنه
هستیشناسی دامنه به عنوان یک طرح مفهومی، وظیفه بازنمایی صریح و رسمی دانش را در یک حوزه تخصصی خاص بر عهده دارد. این رویکرد فراتر از فهرستنویسی ساده، به تعریف دقیق ردهها، ویژگیها و روابط منطقی میان موجودیتهای آن دامنه میپردازد. در واقع، هستیشناسی به ماشین اجازه میدهد تا بفهمد هر مفهوم در دنیای واقعی چه جایگاهی دارد و چگونه با دیگر مفاهیم در ارتباط است.
با استفاده از این مدل، به جای یک نمایهی خطی و ایستا، شبکهای پویا از دانش خلق میشود که امکان پرسوجوهای هوشمندانه را فراهم میسازد. این رویکرد به ویژه در حوزههایی مانند تاریخ که مفاهیم دارای ابعاد زمانی و مکانی پیچیده هستند، کارایی بالایی دارد. هستیشناسی دامنه با ایجاد یک زبان مشترک میان انسان و ماشین، دقت و صحت بازنمایی اطلاعات را به طور چشمگیری ارتقا میدهد.
🔹 3.2. ارتباط هستیشناسی با وب معنایی و گراف دانش
هستیشناسیها به عنوان ستون فقرات وب معنایی، امکان تبدیل دادههای پراکنده به «دادههای پیوندی» و قابل پردازش توسط هوش مصنوعی را فراهم میکنند. این مدلها چارچوبی منطقی ایجاد میکنند که بر اساس آن، گرافهای دانش تشکیل میشوند تا روابط پیچیده میان پدیدهها را ترسیم کنند. بدون وجود یک هستیشناسی قوی، گرافهای دانش تنها مجموعهای از نقاط بدون معنای مشخص خواهند بود.
در دنیای مدرن مدیریت اسناد، پیوند دادن هستیشناسی به وب معنایی باعث میشود که اطلاعات یک آرشیو با منابع دانش جهانی تعاملپذیر شود. این همسویی، زیرساختی حیاتی برای توسعه موتورهای جستجوی معنایی و سیستمهای پاسخگویی به سوالات پژوهشی ایجاد میکند. در حقیقت، هستیشناسی پلی است که اسناد خاکخورده آرشیوی را به گرافهای دانش پیشرفته و زنده در بستر دیجیتال متصل میسازد.
4. هدف پژوهش و دامنه مطالعه 🎯
هدف بنیادین این پژوهش، طراحی و پیادهسازی یک مدل هستیشناسی جامع برای آرشیو دیجیتال مرکز اسناد انقلاب اسلامی ایران است. محققان با بهرهگیری از رویکردی ترکیبی، به دنبال استخراج هوشمند موجودیتها و برقراری پیوندهای معنایی میان آنها برای بهبود بازیابی دانش هستند. این مطالعه با هدف تبدیل منابع سنتی به یک نظام معنایی مدرن انجام شده تا دقت در پاسخگویی به نیازهای کاربران افزایش یابد.
دامنه این مطالعه به طور تخصصی بر تاریخ معاصر ایران، از اواخر دوره پهلوی دوم تا دوران کنونی جمهوری اسلامی تمرکز یافته است. مفاهیم کلیدی شامل رجال سیاسی، احزاب، سازمانهای انقلابی و رویدادهای سرنوشتساز در این بازه زمانی با دقت بالا مدلسازی شدهاند. این مرزبندی دقیق به پژوهش اجازه میدهد تا با دانهبندی جزئی، ساختارهای حکومتی و تحولات اجتماعی را در قالب یک مدل علمی منسجم بازنمایی کند.
5. رویکرد پژوهش: تحلیل متن و بازاستفاده هستیشناسی 🔍
🔹 5.1. رویکرد ترکیبی خودکار و انسانی
این پژوهش از یک متدولوژی آمیخته بهره میبرد که در آن تحلیل متن به صورت نیمهخودکار با نظارت مستقیم خبرگان ترکیب شده است. برای شناسایی موجودیتها، از مدلهای زبانی بزرگ (LLM) و ابزارهای پردازش زبان طبیعی استفاده شده تا حجم انبوه متون با سرعت بالایی پردازش شوند. این مرحله اولیه، زیربنای استخراج ردهها و مفاهیم را از دل اسناد متنی و تاریخ شفاهی فراهم میآورد.
در مرحله دوم، نتایج حاصل از تحلیلهای ماشینی توسط متخصصان و خبرگان حوزه تاریخ معاصر مورد بازبینی و اصلاح قرار گرفته است. این نظارت انسانی تضمین میکند که روابط استخراج شده دارای اعتبار تاریخی بوده و از دقت علمی لازم برخوردار باشند. ترکیب سرعت ماشین و دقتِ تحلیلِ انسانی، منجر به خلق هستیشناسی شده است که هم کارآمد و هم از نظر محتوایی قابل اتکا است.
🔹 5.2. بازاستفاده از مدلها و استانداردهای موجود
در فرآیند طراحی، اصل «بازاستفاده» برای جلوگیری از دوبارهکاری و تضمین انسجام منطقی مدل به طور جدی دنبال شده است. محققان از هستیشناسی شکلی (BFO) به عنوان یک مدل بالادستی برای حفظ ساختار فلسفی و منطقی ردهها الگوبرداری کردهاند. این استاندارد جهانی باعث میشود که هستیشناسی طراحی شده با سایر مدلهای علمی در سطح بینالمللی سازگار و تعاملپذیر باشد.
علاوه بر استاندارد BFO، از چارچوبهای معتبری همچون هستیشناسیهای عمومی برای تعریف مفاهیم بنیادین زمان، مکان و اشخاص استفاده شده است. این رویکرد ادغامی، به مدل پیشنهادی اعتبار علمی مضاعفی میبخشد و آن را از یک طرح محلی به یک ابزار استاندارد تبدیل میکند. بازاستفاده از مدلهای موجود، نه تنها سرعت توسعه را افزایش داده، بلکه منجر به کاهش خطاهای ساختاری در طراحی ردهها گشته است.
6. استخراج موجودیتها از اسناد آرشیوی 📄
🔹 6.1. انواع موجودیتهای شناساییشده
موجودیتهای استخراج شده در این پژوهش طیف گستردهای از عناصر کلیدی تاریخ معاصر ایران را شامل میشوند. این دستهها شامل اشخاص (مانند رهبران، مبارزان و مسئولان)، سازمانها (مانند احزاب و نهادهای انقلابی) و رویدادهای تاریخی (مانند تظاهرات و قراردادها) هستند. همچنین مفاهیم انتزاعی و مکانهای جغرافیایی مرتبط با وقایع نیز به عنوان موجودیتهای مستقل شناسایی و کدگذاری شدهاند.
دادههای مورد نیاز برای این استخراج از منابع متنوعی شامل اسناد مکتوب، تصاویر تاریخی و مصاحبههای تاریخ شفاهی تامین شده است. هر یک از این موجودیتها دارای ویژگیها و روابطی هستند که جایگاه آنها را در تاریخ معاصر تعریف میکند. شناسایی دقیق این عناصر، اولین گام برای تبدیل یک متن ساده آرشیوی به یک گره اطلاعاتی معنادار در گراف دانش نهایی است.
🔹 6.2. نقش OCR و ASR در تحلیل محتوا
فناوری تشخیص کاراکتر نوری (OCR) نقشی کلیدی در تبدیل اسناد کاغذی اسکن شده به متنهای دیجیتال قابل پردازش ایفا کرده است. بدون این ابزار، تحلیل میلیونها برگ سند تاریخی برای ماشین غیرممکن بود؛ اما OCR این امکان را فراهم کرد تا موجودیتها از دل متون قدیمی استخراج شوند. این جهش تکنولوژیک، اسناد خام را به دادههای ساختارمند و قابل جستجو تبدیل کرده است.
همچنین، فناوری تبدیل گفتار به متن (ASR) برای تحلیل هزاران ساعت فایل صوتی مصاحبههای تاریخ شفاهی به کار گرفته شده است. این ابزار به محققان اجازه داد تا محتوای صوتی را به متن تبدیل کرده و سپس مفاهیم و موجودیتها را از درون خاطرات شفاهی استخراج کنند. ترکیب این دو فناوری، پلی میان آرشیوهای سنتی (فیزیکی) و دنیای پردازش معنایی (دیجیتال) ایجاد کرده است.
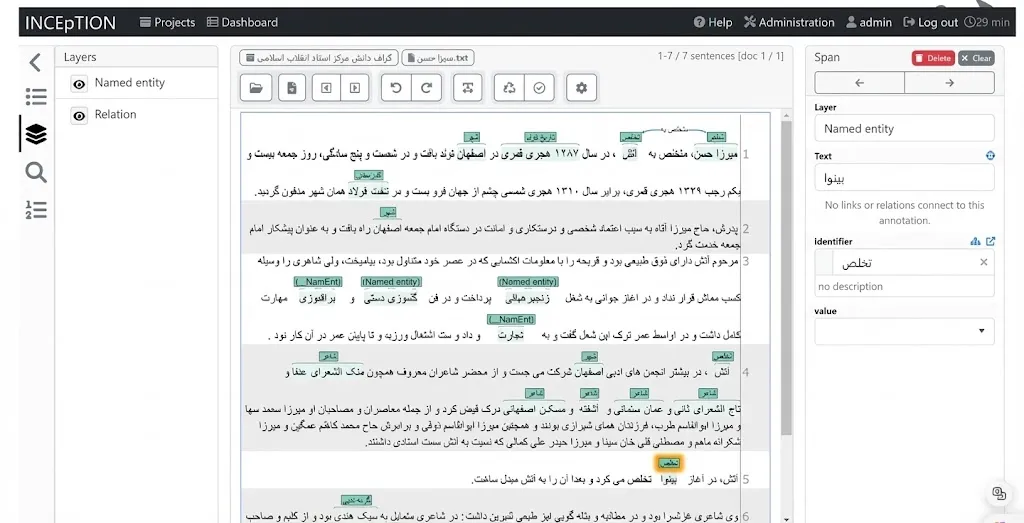
شکل .1 برچسب گذاری با استفاده از نرم افزار متن باز اینسپشن
7. طراحی ساختار سلسلهمراتبی هستیشناسی دامنه 🏗️
🔹 7.1. تعیین دامنه و حدود مفهومی
در ابتدای فرآیند طراحی، مرزهای دقیق هستیشناسی برای مشخص شدن قلمرو پوشش اطلاعاتی تعیین گردید. این مرزبندی به سوالات اساسی پاسخ میدهد که چه مفاهیمی باید در مدل گنجانده شوند و کدام موارد خارج از اولویتهای پژوهشی مرکز هستند. تعیین حدود مفهومی باعث میشود که هستیشناسی از پراکندگی نجات یافته و بر روی نیازهای واقعی پژوهشگران تاریخ متمرکز بماند.
این مرزبندی شامل بازههای زمانی خاص و دستهبندیهای موضوعی اولویتدار در اسناد مرکز انقلاب اسلامی است. با مشخص شدن این قلمرو، محققان توانستند ویژگیها (Properties) و محدودیتهای هر رده را با دقت بیشتری تعریف کنند. این گام حیاتی، تضمینکننده انسجام و کارایی مدل در مراحل بعدی پیادهسازی و بازیابی اطلاعات در محیط آرشیو است.
🔹 7.2. ردهها و زیرردههای اصلی
ساختار سلسلهمراتبی مدل بر پایه حرکت از مفاهیم عام به سمت مفاهیم خاص و جزئی طراحی شده است. در این ساختار، هر موجودیت در یک جایگاه منطقی قرار میگیرد؛ برای مثال، رده «اشخاص» به زیرردههای «سیاسی»، «مذهبی» و «نظامی» تقسیم میشود. این نظم سلسلهمراتبی به ماشین اجازه میدهد تا روابط وراثت را میان مفاهیم درک کرده و جستجوها را هوشمندانه هدایت کند.
دانهبندی (Granularity) در این مدل به حدی دقیق است که حتی نقشهای شغلی و مسئولیتهای افراد نیز به عنوان ردههای جزئی لحاظ شدهاند. عناوینی همچون «وزیر»، «نماینده مجلس» یا «فرمانده نظامی» هر کدام جایگاه منحصر به فرد خود را در سلسلهمراتب دارند. این دقت در طراحی ردهها و زیرردهها، غنای توصیفی فوقالعادهای به هستیشناسی بخشیده و امکان کاوشهای تخصصی در تاریخ را فراهم میکند.
8. بازاستفاده از نظامهای ردهبندی و هستیشناسیها 📚
🔹 8.1. استفاده از DBpedia و Bibframe
در این پژوهش، برای غنای ساختاری از رویکردی ترکیبی شامل تحلیل محتوای دستی و ابزارهای نرمافزاری نظیر Protégé بهره گرفته شده است. محققان با استفاده از پرسوجوهای SPARQL، مفاهیم کلیدی را از فایلهای RDF و OWL استخراج کرده و ساختار سلسلهمراتبی هستیشناسی معتبر DBpedia را به عنوان مبنای اصلی نظمدهی به ردهها قرار دادند.
همچنین، برای تضمین تعاملپذیری در سطح بینالمللی، از مدل کتابشناختی Bibframe جهت توصیف دقیق منابع آرشیوی استفاده شد. این یکپارچهسازی هوشمندانه باعث شد تا مدل پیشنهادی نه تنها با استانداردهای وب معنایی همسو شود، بلکه امکان تبدیل منابع غیرساختارمند آرشیو به دادههای پیوندی و قابل پردازش توسط ماشین را فراهم آورد.
🔹 8.2. بهرهگیری از ردهبندی تاریخ ایران
برای بومیسازی مدل، از ردهبندی کتابخانه کنگره (DSR تاریخ ایران) به عنوان ستون فقراتِ تقسیمبندی دورههای تاریخی استفاده شد. این استاندارد اجازه داد تا وقایع بر اساس توالی زمانی دقیق از دوران پهلوی دوم تا انقالب اسلامی و پس از آن در دوره جمهوری اسلامی به درستی کدگذاری و طبقهبندی شوند.
علاوه بر این، هستیشناسی گراف دانش فارسی (FarsBase) برای تطبیق مفاهیم فرهنگی و زبانی خاص ایران مورد استفاده قرار گرفت. این تلفیق باعث شد هستیشناسی دامنه، ریشههای عمیقی در نظامهای ردهبندی معتبر ملی داشته باشد و موجودیتهایی نظیر گروههای قومی، احزاب داخلی و ساختارهای حکومتی ایران را با دقت بالایی بازنمایی کند.
9. اعتبارسنجی هستیشناسی دامنه ✅
🔹 9.1. مشارکت خبرگان با تکنیک گروه اسمی
به منظور اطمینان از صحت و کارآمدی مدل طراحی شده، فرآیند اعتبارسنجی با مشارکت مستقیم متخصصان حوزه تاریخ معاصر، مدیران و کارشناسان ارشد مرکز اسناد انقلاب اسلامی انجام شد. در این مرحله از تکنیک گروه اسمی (NGT) استفاده گردید تا تمامی موجودیتهای استخراج شده و روابط میان آنها از فیلتر دانشِ تخصصیِ انسانی عبور کرده و اصلاح شوند.
این مشارکت جمعی فراتر از یک نظرسنجی ساده بود و شامل بررسی دقیق «کلیات» (Universals) و حذف افزونگیهای مفهومی در متنهای جامعه هدف گردید. در نهایت، نظرات خبرگان باعث شد تا ردههای استخراج شده از نظر محتوایی و تاریخی با واقعیتهای اسناد آرشیوی کاملاً منطبق شده و سوگیریهای احتمالیِ استخراجِ خودکار برطرف گردد.
🔹 9.2. معیارهای ارزیابی ساختار
ارزیابی نهایی مدل بر پایه چهار محور استوار بود: منطق سلسلهمراتبی، صحت تاریخی-فرهنگی، همترازی و معادلسازی، و در نهایت کامل بودن و سادگی. این معیارها تضمین کردند که هستیشناسی از انسجام منطقی و فلسفی برخوردار بوده و با هستیشناسیهای مشابه جهانی سازگاری کامل داشته باشد.
یکی از اهداف اصلی در این بخش، ایجاد قابلیت فهم همزمان برای انسان و ماشین بود؛ به طوری که تعاریف تدوین شده هم برای پژوهشگران تاریخ قابل درک باشد و هم در یک چارچوب محاسباتی توسط سیستمهای هوش مصنوعی اجرا شود. رعایت این استانداردهای سختگیرانه، زیرساخت لازم برای تبدیل آرشیو دیجیتال به یک نظام معنایی پیشرفته را فراهم کرد.
10. یافتههای پژوهش 📈
🔹 10.1. ردههای افزوده و اصلاحشده
یافتههای اولیه این تحقیق شامل ۵۳۵ رده مفهومی بود که پس از طی مراحل اعتبارسنجی و اصلاح توسط خبرگان، تغییرات گستردهای در آن اعمال شد. در نهایت ۴۵۷ رده مورد تأیید قطعی قرار گرفت و ۷۰ رده جدید برای پوشش خلأهای اطلاعاتی در حوزه تاریخ معاصر به مجموعه اضافه گردید.
همچنین برای بهبود دقت بازیابی، ۵۳ رده در سلسلهمراتب جابجا شدند تا روابط والد-فرزندی منطقیتری برقرار گردد و ۱۹ رده غیرضروری نیز جهت حفظ سادگی مدل حذف شدند. این دانهبندی دقیق به سطحی رسید که مثلاً برای اشخاص، تنها به برچسب «سیاستمدار» بسنده نشده و نقشهای جزئی نظیر رئیسجمهور، وزیر، سفیر یا نماینده مجلس سنا به طور تفکیک شده مدلسازی شدند.
🔹 10.2. غنای مفهومی تاریخ معاصر
این پژوهش با موفقیت توانست خلأ موجود در ادبیات پژوهش داخلی پیرامون طراحی هستیشناسی کاربردی برای اسناد تاریخی را برطرف سازد. مدل نهایی، بستر و زیرساخت منطقی (Foundational Logic) لازم را برای ایجاد یک گراف دانش عظیم در حوزه تاریخ ایران فراهم آورده است که فراتر از جستجوی کلمات کلیدی عمل میکند.
نتایج نشان داد که استفاده از رویکرد ترکیبی (تحلیل متن و بازاستفاده)، غنای مفهومی و دقت بازنمایی دانش را در محیطهای آرشیوی که با ناهمگنی منابع مواجهاند، به طور چشمگیری افزایش میدهد. این دستاورد نه تنها بازیابی اطلاعات را ارتقا میدهد، بلکه پایهای برای توسعه سامانههای هوشمند تصمیمیار و مدیریت دانش تاریخی در کشور خواهد بود.
11. نکات علمی برجسته مقاله 🎓
🔹 رویکرد ترکیبی (Hybrid): استفاده همزمان از تحلیل متن خودکار توسط مدلهای زبانی بزرگ و نظارت انسانی خبرگان.
🔹 استخراج موجودیتها (Named Entity Recognition): شناسایی هوشمند اشخاص، مکانها و رویدادها از متون غیرساختارمند.
🔹 بازاستفاده از هستیشناسیها: بهرهگیری از DBpedia و Bibframe برای تضمین تعاملپذیری بینالمللی.
🔹 دانهبندی (Granularity): طبقهبندی دقیق نقشهای سیاسی و اجتماعی تا جزئیترین سطوح ممکن.
🔹 اعتبارسنجی خبرهمحور: استفاده از تکنیک گروه اسمی برای تطبیق مدل با واقعیتهای تاریخی و فرهنگی.
12. نقش هستیشناسی در توسعه گراف دانش تاریخی 🕸️
هستیشناسی طراحی شده در این تحقیق، به عنوان زیرساخت منطقی و بنیادین برای خلق یک گراف دانش عظیم در حوزه تاریخ معاصر ایران عمل میکند. این مدل با تعریف دقیق روابط معنایی میان موجودیتها، اجازه میدهد تا دادههای پراکنده و خام آرشیوی به یک شبکه دانش متصل و هوشمند تبدیل شوند. با ایجاد این بستر، محققان میتوانند پیوندهای پنهان و زنجیرهای میان هزاران واقعه و شخصیت تاریخی را که پیش از این در انبوه اسناد مخفی مانده بودند، با دقت ریاضی و منطقی کشف و تحلیل نمایند. 🏛️
با پیادهسازی این مدل، پارادایم بازیابی اطلاعات از حالت سنتی (جستجوی کلمات کلیدی) به سمت جستجوی معنایی و هوشمند تغییر جهت میدهد. این تحول بنیادین، پایه و اساسی برای توسعه موتورهای جستجوی پیشرفته و سیستمهای هوش مصنوعی فراهم میکند که قادرند به پرسشهای پیچیده پژوهشگران پاسخهای دقیق و مستند بدهند. در واقع، این گراف دانش نه تنها دسترسی به اسناد را تسهیل میکند، بلکه به عنوان یک ابزار تصمیمیار برای تحلیلگران تاریخ معاصر، راه را برای تولید دانش جدید و بازخوانی دقیقتر وقایع تاریخی هموار میسازد. 🚀
13. نتیجهگیری 🔚
این پژوهش با ارائه یک مدل هستیشناسی دامنه، گامی بلند در جهت نوسازی نظامهای بازیابی اطلاعات در آرشیوهای تاریخی برداشته است. نتایج حاصله نشان میدهد که رویکرد ترکیبی میتواند به طور موثری چالشهای ناهمگنی منابع و ابهام معنایی را برطرف کند.
دستاورد نهایی این مطالعه، ایجاد پایهای استوار برای گراف دانش تاریخی ایران است که زمینهساز توسعه سامانههای هوشمند پژوهشی خواهد بود. این مدل نه تنها برای مرکز اسناد انقلاب اسلامی، بلکه برای تمامی دامنههای مشابه در آرشیوهای دیجیتال قابل توسعه است
👥 نویسندگان مقاله
🎓 علیرضا انتهایی سرای
دانشجوی دکتری رشته علم اطلاعات و دانششناسی، گرایش بازیابی اطلاعات و دانششناسی، دانشگاه تهران
(نویسنده مسئول)
🎓 نادر نقشینه
دانشیار گروه علم اطلاعات و دانششناسی، دانشکده مدیریت، دانشگاه تهران
🎓 بهروز مینایی بیدگلی
استاد تمام گروه هوش مصنوعی و رباتیک، دانشکده مهندسی کامپیوتر، دانشگاه علم و صنعت ایران
🎓 علی شعبانی
استادیار گروه علم اطلاعات و دانششناسی، دانشکده مدیریت، دانشگاه تهران