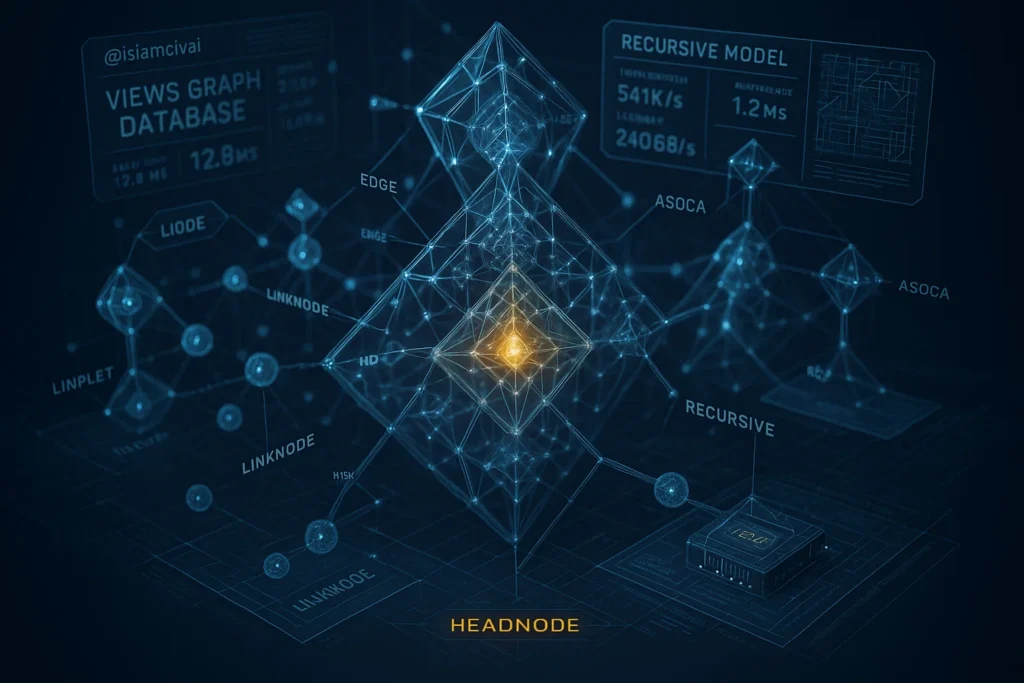
مدل سختافزارپسند پایگاه داده گرافی «Views» برای پردازش معنایی 🧠💾
علاوه بر این، ویژگیهای دیگری مثل چندرسانهایبودن دادهها، چند-مودالیتهٔ درونساختاری و مسئلهٔ میانعملیپذیری بین پایگاهها (inter-database interoperability) نیز بر مقیاسپذیری و کارایی افزودهاند. برخی از راهحلهای فعلی برای بارهای کاری گرافی شامل خوشههای GPU هستند، اما هزینهٔ انرژی و ساخت آنها مانع از استفادهٔ گستردهشان میشود. در نتیجه، بهجای تکیه صرف بر شتابدهندههای عمومی، نیاز به طراحی دادهساختارهایی است که «طراحیشده برای سختافزار» (hardware-friendly) باشند و بتوان آنها را با پردازش در/نزدیک حافظه (in-/near-memory computing) و موازیسازی شدید ترکیب کرد.
برای رفع این چالشها، در این پژوهش مدل جدیدی به نام Views معرفی میشود که ساختار آن برای پیادهسازی سختافزاری و پردازش کارآمد دادههای گرافی طراحی شده است. Views با بازتعریف واحد رابطهای پایه (triplet) و نگاشت آن به ساختارهای پیوندی (linked-list) جهتدار، امکان پیمایش و پردازشهای موازی سطح پایین را فراهم میآورد؛ در نتیجه هم کاراییِ ذخیرهسازی افزایش مییابد و هم عملیات پرسوجو و استنتاج معنایی سریعتر و کمهزینهتر قابل اجرا خواهد بود.
ویژگیهای مدل Views 💡
مدل Views بر اساس گرافهای جهتدار و برچسبپذیر ساخته شده است که قابلیت تعریف ویژگیهای بازگشتی (Recursive Properties) را فراهم میکنند. این ویژگی باعث میشود مدل بتواند روابط پیچیده، تو در تو و سلسلهمراتبی را بهصورت طبیعی نمایش دهد. در نتیجه، Views علاوه بر گرافهای متداول، توانایی نمایش گرافهای چرخهای جهتدار (DAG) و نیز گرافهایی با روابط عمیق و چندلایه را دارد.
ساختار داده سهتایی (Triplet)
در قلب Views، یک رابطهٔ سهتایی (source – edge – destination) بهعنوان واحد پایه اطلاعاتی در گراف در نظر گرفته میشود. این ساختار معادل RDF triple (subject–predicate–object) است، اما تفاوت مهم اینجاست که در Views تمام اجزا — چه راس مقصد و چه یال — بهصورت یکنواخت و عددی در حافظه فیزیکی ذخیره میشوند. این یکنواختی، زمینهٔ پیادهسازی سختافزارپسند را فراهم میکند.
لینکنود (Linknode) و هدنود (Headnode) 🔗
Linknode: شامل اطلاعات مربوط به منبع، یال، مقصد و یک اشارهگر به لینکنود بعدی (next pointer) است. این اشارهگر امکان پیمایش متوالی زنجیرهها را حتی زمانی که در حافظه پراکنده ذخیره شدهاند، فراهم میکند.
Headnode: نقطهی شروع هر زنجیره در گراف است که وجود یک موجودیت را در پایگاه داده نشان میدهد. در هدنود، شناسهٔ منبع (head ID) به آدرس خودش اشاره میکند و primIDها تهی هستند.
در Views، هر راس با درجه δ معادل یک زنجیره با طول δ+1 خواهد بود، چراکه یک هدنود + δ لینکنود به آن متصل میشوند. پایان هر زنجیره نیز با مقدار ویژهای به نام EOC (End of Chain) مشخص میشود که مشابه علامت پایان فایل در سیستمهای ذخیرهسازی عمل میکند.
این طراحی امکان پیمایش کارآمد در گراف، کشف ویژگیهای هر راس و اجرای پرسوجوهای رابطهای را بدون نیاز به جستوجوی کل حافظه فراهم میکند.
قابلیت برچسبگذاری بازگشتی 🏷️
یکی از مهمترین نقاط قوت Views، قابلیت برچسبگذاری بازگشتی (Recursive Labelling) است. در این رویکرد، نه تنها خود رئوس و یالها میتوانند دارای برچسب باشند، بلکه این برچسبها نیز قادرند ویژگیهای بیشتری را در قالب زنجیرههای فرعی (sub-chains) داشته باشند. این انعطافپذیری به Views توانایی نمایش روابط بسیار پیچیده و چندلایه را میدهد.
بهطور مشخص:
- هر یال یا راس میتواند ویژگیهای مخصوص به خود را داشته باشد. برای مثال، یک یال «عضویت در خانواده» میتواند شامل اطلاعات جانبی مانند «ردهٔ زیستشناسی» یا «بخش گفتاری» باشد.
- زنجیرههای فرعی (sub-chains) برای نمایش اطلاعات وابسته ساخته میشوند؛ بدین معنا که هر ویژگی میتواند خود به یک زنجیرهٔ کامل از ویژگیها اشاره کند.
- روابط پیچیده بهصورت سلسلهمراتبی و قابل گسترش ذخیره و پردازش میشوند، بهطوریکه هر زنجیره میتواند بینهایت لایهٔ فرعی داشته باشد (∞).
نقش prop1 و prop2
در ساختار لینکنود کامل، دو اشارهگر ویژه تعریف میشوند:
prop1: برای ذخیرهٔ ویژگیهای یال یا برچسب آن.
prop2: برای ذخیرهٔ ویژگیهای راس مقصد در همان رابطه.
این دو اشارهگر به لینکنودهای دیگری هدایت میشوند که خصوصیات درونزمینهای (context-specific) را توضیح میدهند. به این ترتیب، Views قادر است همزمان اطلاعات کلی (context-free) و اطلاعات وابسته به زمینه (context-dependent) را نمایش دهد.
مثال کاربردی 🍲
بهعنوان نمونه، جملهی زیر را در نظر بگیرید:
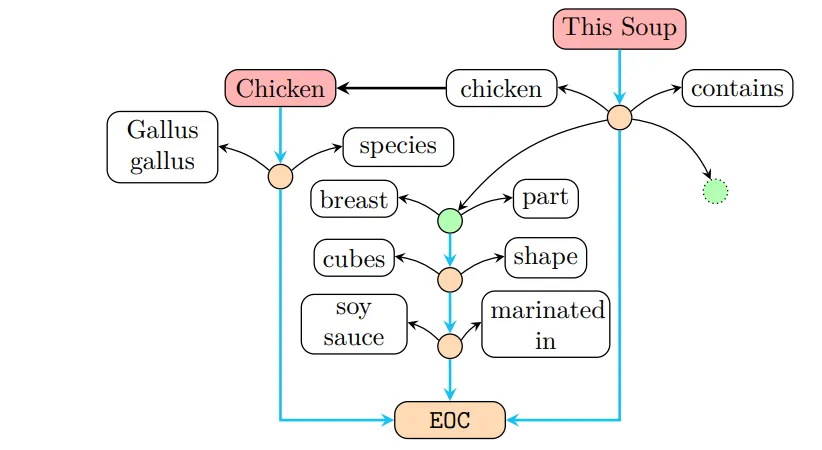
«این سوپ حاوی مرغ است و مرغ شامل سینه، بهصورت مکعبی و در سس سویا مزهدار شده است.»
در Views، این جمله بهصورت یک زنجیرهٔ اصلی (Soup → contains → Chicken) نمایش داده میشود و سپس ویژگیهای مرغ (سینه، شکل مکعبی، مزهدار در سس سویا) هرکدام بهعنوان یک زیرزنجیره (sub-chain) از گرهی «Chicken» ذخیره میشوند.
پیادهسازی سختافزاری ⚙️
مدل Views از ابتدا با هدف سازگاری با سختافزار و افزایش سرعت پردازش طراحی شده است. این مدل با استفاده از معماری ASOCA (Associative Chip Architecture) در تراشهها پیادهسازی میشود. ویژگی اصلی این معماری، پشتیبانی از پردازش نزدیکبهحافظه (Near-Memory Computing) است که امکان ذخیرهسازی و پردازش دادههای گرافی را بهصورت همزمان و موازی فراهم میسازد.
| نوع/کارکرد | شناسه | نگاشت لینکنود | کاربرد |
|---|---|---|---|
| محتوا (Content) | C1 / C2 | primID1 / primID2 | راس یال / راس مقصد |
| راهبری (Navigator) | N1 / N2 | head ID / next | راس مبدا / لینکنود بعدی |
| زیرمجموعه (Subordinate) | S1 / S2 | prop1 / prop2 | زیرزنجیره یال / زیرزنجیره مقصد |
| متفرقه (Miscellaneous) | M1 / M2 | prop1 / prop2 | ویژگیهای عمومی یال / مقصد |
روشهای نگاشت دادهها
برای پیادهسازی Views روی سختافزار، دو روش اصلی در نظر گرفته شده است:
CNSM Allocation: در این روش، عناصر مختلف لینکنود در آرایههای جداگانه ذخیره میشوند. به این ترتیب، پیمایش و بازیابی اطلاعات سریعتر و کاراتر انجام میشود. آرایهها به چهار گروه تقسیم میشوند: C (Content)، N (Navigator)، S (Subordinate)، و M (Miscellaneous).
Normalised Allocation: این نسخه سادهتر است و تنها شامل آرایههای C و N میشود. در نتیجه، حجم حافظه کاهش مییابد اما انعطافپذیری برای ذخیرهٔ ویژگیهای پیچیده کمتر خواهد بود. این نگاشت بیشتر برای پایگاههای داده کوچک یا دادههای با ساختار ساده کاربرد دارد.
تراشه ASOCA 🖥️
مدل Views در عمل با استفاده از دو نسل از تراشههای ASOCA پیادهسازی شده است:
ASOCA1: یک حافظه انجمنی اولیه (Associative Memory Chip I) که شامل آرایههای کوچک و دوبخشی است. این تراشه بهعنوان «واحد ذخیرهسازی پایه» عمل میکند و هر آرایه میتواند مجموعهای از اشارهگرها را نگه دارد.
ASOCA2: نسخهٔ پیشرفتهتر که Views را روی گروهی از ۸× ASOCA1 (موسوم به supercluster) نگاشت میکند. هر سوپرکلاستر ۶۴ لینکنود را ذخیره کرده و عملیات موازی مثل جستوجوی محتوامحور (CAR) یا جستوجوی ترکیبی (CAR2) را اجرا میکند. این تراشه علاوه بر ذخیرهسازی، شامل واحدهای پردازش نزدیکبهحافظه است که بهطور مستقیم روی دادههای گرافی عملیات انجام میدهند.
این معماری موجب میشود پرسوجوهایی مانند «تمام اطلاعات مربوط به Tom Hanks را بیاور» یا «چه کسی دو جایزه اسکار برده است؟» بهصورت موازی و بسیار سریع پاسخ داده شوند.
کاربردهای مدل Views 🤖
۱. استدلال معنایی (Semantic Reasoning)
یکی از ظرفیتهای مهم Views، توانایی در اجرای استنتاج منطقی و استدلال معنایی است. در این رویکرد، روابط بین موجودیتها نه صرفاً بهصورت دادههای ایستا، بلکه بهعنوان زنجیرههای قابل پردازش نمایش داده میشوند.
برای مثال:
- مقدمه ۱: «این یک گربه است.»
- مقدمه ۲: «گربهها پستاندار هستند.»
- نتیجه: «این یک پستاندار است.»
در Views، این استنتاج از طریق عملیات جستوجوی محتوامحور و ترکیبی (CAR, CAR2) و بازیابی آدرسها (AAR) انجام میشود. ابتدا سیستم بررسی میکند که «این» عضو چه گونهای (species) است، سپس از طریق زنجیرهٔ مربوط به «گربه»، خانواده (Felidae) یا طبقهبندی زیستی آن استخراج میشود. در نهایت، نتیجهگیری بهصورت نمادین بازسازی میشود. این فرایند دقیقاً همان چیزی است که در منطق صوری با قیاس (syllogism) انجام میدهیم، اما اینبار بر پایهٔ ساختار دادهٔ سختافزارپسند.
۲. پردازش شناختی (مدل Copycat)
مدل Copycat یک مدل شناختی است که برای شبیهسازی فرایندهای قیاس انسانی طراحی شده است. این مدل روی مفاهیم «شفاف و نمادین» کار میکند و از ساختاری به نام Slipnet بهره میگیرد.
مفهوم کلیدی در Copycat، Slippage (لغزش مفهومی) است. این مکانیزم اجازه میدهد که یک مفهوم در حین استدلال با مفهومی مرتبط جایگزین شود. برای مثال، اگر در یک قیاس بهدنبال «آخرین حرف» باشیم، سیستم میتواند با لغزش، آن را به «اولین حرف» جایگزین کند، چون این دو مفهوم از طریق رابطهٔ «Opposite» در Slipnet بههم متصل هستند.
در Views، Slipnet بهصورت یک پایگاه داده گرافی قابل پیادهسازی است:
- هر مفهوم (Slipnode) بهعنوان یک Headnode ذخیره میشود.
- روابط مفهومی مانند «First – Opposite – Last» بهصورت Linknode نمایش داده میشوند.
- ویژگیهایی مانند میزان فعالسازی (Activation)، عمق مفهومی (Conceptual Depth) و قفل لغزش (Slip Lock) بهعنوان ویژگیهای عمومی (M arrays) ذخیره میشوند.
این ساختار امکان اجرای فرایندهای شناختی مانند فعالسازی (Activation Spread) و لغزش (Slippage) را روی سختافزار فراهم میکند و میتواند مدلهای شناختی پیچیده را تسریع کند.
مقایسه و سازگاری 📊
مدل Views را میتوان یک مدل «سهتایی+» (Triplet⁺) دانست؛ یعنی گسترشیافتهٔ RDF Triple که محدودیتهای آن را برطرف کرده و امکانات جدیدی برای ذخیرهسازی و پردازش دادهها ارائه میدهد. در حالیکه RDF عمدتاً بر نمایش نمادین روابط متمرکز است، Views علاوه بر نمایش، امکان پردازش کارآمد در سطح سختافزار و پشتیبانی از ویژگیهای بازگشتی را فراهم میکند.
از سوی دیگر، Views از نظر ساختاری شباهتهایی با لیستهای پیوندی (Linked Lists) در زبان Lisp دارد. هر زنجیره در Views مانند یک لیست است که از طریق اشارهگرهای next، prop1 و prop2 میتواند گسترش یابد. اما برخلاف لیستهای سنتی Lisp، Views برای نگاشت مستقیم روی حافظه و پردازش موازی طراحی شده است. همین ویژگی باعث میشود Views نقشی همچون پل میان دادههای ایستا (Static Data Representation) و پردازشهای پویا (Dynamic Processing) مثل λ-calculus ایفا کند.
به بیان دیگر، Views را میتوان ترکیبی از انعطاف RDF و کارایی Lisp دانست؛ مدلی که هم برای بازنمایی معنایی مناسب است و هم برای اجرا روی تراشههای محاسباتی بهینهسازی شده است.
نتیجهگیری 🛡️
مدل گرافی Views یک ساختار دادهٔ سختافزارپسند (Hardware-Friendly) است که با طراحی ویژهاش میتواند محدودیتهای مدلهای گرافی سنتی را پشت سر بگذارد. این مدل:
- از گرافهای برچسبپذیر بازگشتی پشتیبانی میکند و امکان نمایش روابط پیچیده و سلسلهمراتبی را فراهم میسازد.
- قابلیت پیادهسازی کارآمد روی سختافزار را دارد و بهطور مستقیم با معماریهایی همچون ASOCA سازگار است.
- اجرای عملیات موازی و جستوجوهای سریع را امکانپذیر میسازد و در نتیجه، کارایی پرسوجوها و پردازشها را بهشدت افزایش میدهد.
- برای کاربردهای هوش مصنوعی همچون استدلال معنایی، پردازش شناختی و شبیهسازی مدلهای قیاسی کاملاً مناسب است.
از این رو، Views میتواند بهعنوان پلی میان علوم کامپیوتر (ساختار داده و الگوریتمها)، هوش مصنوعی (نمادین و ترکیبی) و طراحی سختافزار (پردازش نزدیکبهحافظه و تراشههای انجمنی) عمل کند. این همگرایی مسیر تازهای برای توسعهی پایگاههای داده گرافی نسل آینده و شتابدهی سختافزاری در هوش مصنوعی باز خواهد کرد.
✅
مدل سختافزارپسند پایگاه داده گرافی «Views» برای پردازش معنایی 🧠💾
علاوه بر این، ویژگیهای دیگری مثل چندرسانهایبودن دادهها، چند-مودالیتهٔ درونساختاری و مسئلهٔ میانعملیپذیری بین پایگاهها (inter-database interoperability) نیز بر مقیاسپذیری و کارایی افزودهاند. برخی از راهحلهای فعلی برای بارهای کاری گرافی شامل خوشههای GPU هستند، اما هزینهٔ انرژی و ساخت آنها مانع از استفادهٔ گستردهشان میشود. در نتیجه، بهجای تکیه صرف بر شتابدهندههای عمومی، نیاز به طراحی دادهساختارهایی است که «طراحیشده برای سختافزار» (hardware-friendly) باشند و بتوان آنها را با پردازش در/نزدیک حافظه (in-/near-memory computing) و موازیسازی شدید ترکیب کرد.
برای رفع این چالشها، در این پژوهش مدل جدیدی به نام Views معرفی میشود که ساختار آن برای پیادهسازی سختافزاری و پردازش کارآمد دادههای گرافی طراحی شده است. Views با بازتعریف واحد رابطهای پایه (triplet) و نگاشت آن به ساختارهای پیوندی (linked-list) جهتدار، امکان پیمایش و پردازشهای موازی سطح پایین را فراهم میآورد؛ در نتیجه هم کاراییِ ذخیرهسازی افزایش مییابد و هم عملیات پرسوجو و استنتاج معنایی سریعتر و کمهزینهتر قابل اجرا خواهد بود.
ویژگیهای مدل Views 💡
مدل Views بر اساس گرافهای جهتدار و برچسبپذیر ساخته شده است که قابلیت تعریف ویژگیهای بازگشتی (Recursive Properties) را فراهم میکنند. این ویژگی باعث میشود مدل بتواند روابط پیچیده، تو در تو و سلسلهمراتبی را بهصورت طبیعی نمایش دهد. در نتیجه، Views علاوه بر گرافهای متداول، توانایی نمایش گرافهای چرخهای جهتدار (DAG) و نیز گرافهایی با روابط عمیق و چندلایه را دارد.
ساختار داده سهتایی (Triplet)
در قلب Views، یک رابطهٔ سهتایی (source – edge – destination) بهعنوان واحد پایه اطلاعاتی در گراف در نظر گرفته میشود. این ساختار معادل RDF triple (subject–predicate–object) است، اما تفاوت مهم اینجاست که در Views تمام اجزا — چه راس مقصد و چه یال — بهصورت یکنواخت و عددی در حافظه فیزیکی ذخیره میشوند. این یکنواختی، زمینهٔ پیادهسازی سختافزارپسند را فراهم میکند.
لینکنود (Linknode) و هدنود (Headnode) 🔗
Linknode: شامل اطلاعات مربوط به منبع، یال، مقصد و یک اشارهگر به لینکنود بعدی (next pointer) است. این اشارهگر امکان پیمایش متوالی زنجیرهها را حتی زمانی که در حافظه پراکنده ذخیره شدهاند، فراهم میکند.
Headnode: نقطهی شروع هر زنجیره در گراف است که وجود یک موجودیت را در پایگاه داده نشان میدهد. در هدنود، شناسهٔ منبع (head ID) به آدرس خودش اشاره میکند و primIDها تهی هستند.
در Views، هر راس با درجه δ معادل یک زنجیره با طول δ+1 خواهد بود، چراکه یک هدنود + δ لینکنود به آن متصل میشوند. پایان هر زنجیره نیز با مقدار ویژهای به نام EOC (End of Chain) مشخص میشود که مشابه علامت پایان فایل در سیستمهای ذخیرهسازی عمل میکند.
این طراحی امکان پیمایش کارآمد در گراف، کشف ویژگیهای هر راس و اجرای پرسوجوهای رابطهای را بدون نیاز به جستوجوی کل حافظه فراهم میکند.
قابلیت برچسبگذاری بازگشتی 🏷️
یکی از مهمترین نقاط قوت Views، قابلیت برچسبگذاری بازگشتی (Recursive Labelling) است. در این رویکرد، نه تنها خود رئوس و یالها میتوانند دارای برچسب باشند، بلکه این برچسبها نیز قادرند ویژگیهای بیشتری را در قالب زنجیرههای فرعی (sub-chains) داشته باشند. این انعطافپذیری به Views توانایی نمایش روابط بسیار پیچیده و چندلایه را میدهد.
بهطور مشخص:
- هر یال یا راس میتواند ویژگیهای مخصوص به خود را داشته باشد. برای مثال، یک یال «عضویت در خانواده» میتواند شامل اطلاعات جانبی مانند «ردهٔ زیستشناسی» یا «بخش گفتاری» باشد.
- زنجیرههای فرعی (sub-chains) برای نمایش اطلاعات وابسته ساخته میشوند؛ بدین معنا که هر ویژگی میتواند خود به یک زنجیرهٔ کامل از ویژگیها اشاره کند.
- روابط پیچیده بهصورت سلسلهمراتبی و قابل گسترش ذخیره و پردازش میشوند، بهطوریکه هر زنجیره میتواند بینهایت لایهٔ فرعی داشته باشد (∞).
نقش prop1 و prop2
در ساختار لینکنود کامل، دو اشارهگر ویژه تعریف میشوند:
prop1: برای ذخیرهٔ ویژگیهای یال یا برچسب آن.
prop2: برای ذخیرهٔ ویژگیهای راس مقصد در همان رابطه.
این دو اشارهگر به لینکنودهای دیگری هدایت میشوند که خصوصیات درونزمینهای (context-specific) را توضیح میدهند. به این ترتیب، Views قادر است همزمان اطلاعات کلی (context-free) و اطلاعات وابسته به زمینه (context-dependent) را نمایش دهد.
مثال کاربردی 🍲
بهعنوان نمونه، جملهی زیر را در نظر بگیرید:
«این سوپ حاوی مرغ است و مرغ شامل سینه، بهصورت مکعبی و در سس سویا مزهدار شده است.»
در Views، این جمله بهصورت یک زنجیرهٔ اصلی (Soup → contains → Chicken) نمایش داده میشود و سپس ویژگیهای مرغ (سینه، شکل مکعبی، مزهدار در سس سویا) هرکدام بهعنوان یک زیرزنجیره (sub-chain) از گرهی «Chicken» ذخیره میشوند.
پیادهسازی سختافزاری ⚙️
مدل Views از ابتدا با هدف سازگاری با سختافزار و افزایش سرعت پردازش طراحی شده است. این مدل با استفاده از معماری ASOCA (Associative Chip Architecture) در تراشهها پیادهسازی میشود. ویژگی اصلی این معماری، پشتیبانی از پردازش نزدیکبهحافظه (Near-Memory Computing) است که امکان ذخیرهسازی و پردازش دادههای گرافی را بهصورت همزمان و موازی فراهم میسازد.
| نوع/کارکرد | شناسه | نگاشت لینکنود | کاربرد |
|---|---|---|---|
| محتوا (Content) | C1 | primID1 | اشارهگر راس یال |
| C2 | primID2 | اشارهگر راس مقصد | |
| راهبری (Navigator) | N1 | head ID | اشارهگر راس مبدا |
| N2 | next | اشارهگر لینکنود بعدی | |
| زیرمجموعه (Subordinate) | S1 | prop1 | زیرزنجیره یال |
| S2 | prop2 | زیرزنجیره مقصد | |
| متفرقه (Miscellaneous) | M1 | prop1 | ویژگیهای عمومی یال |
| M2 | prop2 | ویژگیهای عمومی مقصد |
روشهای نگاشت دادهها
برای پیادهسازی Views روی سختافزار، دو روش اصلی در نظر گرفته شده است:
CNSM Allocation: در این روش، عناصر مختلف لینکنود در آرایههای جداگانه ذخیره میشوند. به این ترتیب، پیمایش و بازیابی اطلاعات سریعتر و کاراتر انجام میشود. آرایهها به چهار گروه تقسیم میشوند: C (Content)، N (Navigator)، S (Subordinate)، و M (Miscellaneous).
Normalised Allocation: این نسخه سادهتر است و تنها شامل آرایههای C و N میشود. در نتیجه، حجم حافظه کاهش مییابد اما انعطافپذیری برای ذخیرهٔ ویژگیهای پیچیده کمتر خواهد بود. این نگاشت بیشتر برای پایگاههای داده کوچک یا دادههای با ساختار ساده کاربرد دارد.
تراشه ASOCA 🖥️
مدل Views در عمل با استفاده از دو نسل از تراشههای ASOCA پیادهسازی شده است:
ASOCA1: یک حافظه انجمنی اولیه (Associative Memory Chip I) که شامل آرایههای کوچک و دوبخشی است. این تراشه بهعنوان «واحد ذخیرهسازی پایه» عمل میکند و هر آرایه میتواند مجموعهای از اشارهگرها را نگه دارد.
ASOCA2: نسخهٔ پیشرفتهتر که Views را روی گروهی از ۸× ASOCA1 (موسوم به supercluster) نگاشت میکند. هر سوپرکلاستر ۶۴ لینکنود را ذخیره کرده و عملیات موازی مثل جستوجوی محتوامحور (CAR) یا جستوجوی ترکیبی (CAR2) را اجرا میکند. این تراشه علاوه بر ذخیرهسازی، شامل واحدهای پردازش نزدیکبهحافظه است که بهطور مستقیم روی دادههای گرافی عملیات انجام میدهند.
این معماری موجب میشود پرسوجوهایی مانند «تمام اطلاعات مربوط به Tom Hanks را بیاور» یا «چه کسی دو جایزه اسکار برده است؟» بهصورت موازی و بسیار سریع پاسخ داده شوند.
کاربردهای مدل Views 🤖
۱. استدلال معنایی (Semantic Reasoning)
یکی از ظرفیتهای مهم Views، توانایی در اجرای استنتاج منطقی و استدلال معنایی است. در این رویکرد، روابط بین موجودیتها نه صرفاً بهصورت دادههای ایستا، بلکه بهعنوان زنجیرههای قابل پردازش نمایش داده میشوند.
برای مثال:
- مقدمه ۱: «این یک گربه است.»
- مقدمه ۲: «گربهها پستاندار هستند.»
- نتیجه: «این یک پستاندار است.»
در Views، این استنتاج از طریق عملیات جستوجوی محتوامحور و ترکیبی (CAR, CAR2) و بازیابی آدرسها (AAR) انجام میشود. ابتدا سیستم بررسی میکند که «این» عضو چه گونهای (species) است، سپس از طریق زنجیرهٔ مربوط به «گربه»، خانواده (Felidae) یا طبقهبندی زیستی آن استخراج میشود. در نهایت، نتیجهگیری بهصورت نمادین بازسازی میشود. این فرایند دقیقاً همان چیزی است که در منطق صوری با قیاس (syllogism) انجام میدهیم، اما اینبار بر پایهٔ ساختار دادهٔ سختافزارپسند.
۲. پردازش شناختی (مدل Copycat)
مدل Copycat یک مدل شناختی است که برای شبیهسازی فرایندهای قیاس انسانی طراحی شده است. این مدل روی مفاهیم «شفاف و نمادین» کار میکند و از ساختاری به نام Slipnet بهره میگیرد.
مفهوم کلیدی در Copycat، Slippage (لغزش مفهومی) است. این مکانیزم اجازه میدهد که یک مفهوم در حین استدلال با مفهومی مرتبط جایگزین شود. برای مثال، اگر در یک قیاس بهدنبال «آخرین حرف» باشیم، سیستم میتواند با لغزش، آن را به «اولین حرف» جایگزین کند، چون این دو مفهوم از طریق رابطهٔ «Opposite» در Slipnet بههم متصل هستند.
در Views، Slipnet بهصورت یک پایگاه داده گرافی قابل پیادهسازی است:
- هر مفهوم (Slipnode) بهعنوان یک Headnode ذخیره میشود.
- روابط مفهومی مانند «First – Opposite – Last» بهصورت Linknode نمایش داده میشوند.
- ویژگیهایی مانند میزان فعالسازی (Activation)، عمق مفهومی (Conceptual Depth) و قفل لغزش (Slip Lock) بهعنوان ویژگیهای عمومی (M arrays) ذخیره میشوند.
این ساختار امکان اجرای فرایندهای شناختی مانند فعالسازی (Activation Spread) و لغزش (Slippage) را روی سختافزار فراهم میکند و میتواند مدلهای شناختی پیچیده را تسریع کند.
مقایسه و سازگاری 📊
مدل Views را میتوان یک مدل «سهتایی+» (Triplet⁺) دانست؛ یعنی گسترشیافتهٔ RDF Triple که محدودیتهای آن را برطرف کرده و امکانات جدیدی برای ذخیرهسازی و پردازش دادهها ارائه میدهد. در حالیکه RDF عمدتاً بر نمایش نمادین روابط متمرکز است، Views علاوه بر نمایش، امکان پردازش کارآمد در سطح سختافزار و پشتیبانی از ویژگیهای بازگشتی را فراهم میکند.
از سوی دیگر، Views از نظر ساختاری شباهتهایی با لیستهای پیوندی (Linked Lists) در زبان Lisp دارد. هر زنجیره در Views مانند یک لیست است که از طریق اشارهگرهای next، prop1 و prop2 میتواند گسترش یابد. اما برخلاف لیستهای سنتی Lisp، Views برای نگاشت مستقیم روی حافظه و پردازش موازی طراحی شده است. همین ویژگی باعث میشود Views نقشی همچون پل میان دادههای ایستا (Static Data Representation) و پردازشهای پویا (Dynamic Processing) مثل λ-calculus ایفا کند.
به بیان دیگر، Views را میتوان ترکیبی از انعطاف RDF و کارایی Lisp دانست؛ مدلی که هم برای بازنمایی معنایی مناسب است و هم برای اجرا روی تراشههای محاسباتی بهینهسازی شده است.
نتیجهگیری 🛡️
مدل گرافی Views یک ساختار دادهٔ سختافزارپسند (Hardware-Friendly) است که با طراحی ویژهاش میتواند محدودیتهای مدلهای گرافی سنتی را پشت سر بگذارد. این مدل:
- از گرافهای برچسبپذیر بازگشتی پشتیبانی میکند و امکان نمایش روابط پیچیده و سلسلهمراتبی را فراهم میسازد.
- قابلیت پیادهسازی کارآمد روی سختافزار را دارد و بهطور مستقیم با معماریهایی همچون ASOCA سازگار است.
- اجرای عملیات موازی و جستوجوهای سریع را امکانپذیر میسازد و در نتیجه، کارایی پرسوجوها و پردازشها را بهشدت افزایش میدهد.
- برای کاربردهای هوش مصنوعی همچون استدلال معنایی، پردازش شناختی و شبیهسازی مدلهای قیاسی کاملاً مناسب است.
از این رو، Views میتواند بهعنوان پلی میان علوم کامپیوتر (ساختار داده و الگوریتمها)، هوش مصنوعی (نمادین و ترکیبی) و طراحی سختافزار (پردازش نزدیکبهحافظه و تراشههای انجمنی) عمل کند. این همگرایی مسیر تازهای برای توسعهی پایگاههای داده گرافی نسل آینده و شتابدهی سختافزاری در هوش مصنوعی باز خواهد کرد.
✅