یادگیری برای پرسیدن (Learning to Ask): فصل جدیدی در همکاری انسان و هوش مصنوعی
چارچوب نوآورانهای که نحوه تعامل انسان و هوش مصنوعی را بازتعریف میکند
مقدمه: فراتر از یک انتخاب ساده بین انسان و ماشین
تصور کنید در یک بخش اورژانس شلوغ هستید. یک سیستم هوش مصنوعی به پزشکان در فرآیند تریاژ و اولویتبندی بیماران کمک میکند. این سیستم به حجم عظیمی از دادههای پزشکی دسترسی دارد و میتواند الگوهایی را تشخیص دهد که از چشم انسان پنهان میمانند. اما پزشک حاضر در صحنه به اطلاعاتی دسترسی دارد که در هیچ پایگاه دادهای ثبت نشده است: رنگپریدگی چهره بیمار، لحن صدای او هنگام شرح درد، یا سابقه پزشکی شفاهی که بیمار ارائه میدهد. در چنین شرایطی، سیستم چگونه باید عمل کند؟ آیا باید به تنهایی تصمیم بگیرد یا کل فرآیند را به پزشک واگذار کند؟
چالش سیستمهای پشتیبان تصمیمگیری در دنیای واقعی
هدف نهایی در همکاری انسان و هوش مصنوعی، رسیدن به نقطهای است که ترکیب تواناییهای هر دو، نتیجهای بهتر از عملکرد فردی هر یک به همراه داشته باشد. این همان مفهوم عملکرد مکمل است. انسانها در استدلال شهودی، درک زمینه و استفاده از اطلاعات غیرساختاریافته مهارت دارند، در حالی که ماشینها در پردازش سریع دادههای حجیم و شناسایی الگوهای پیچیده بیرقیب هستند. چالش اصلی این است که چگونه و چه زمانی این دو توانایی منحصربهفرد را با هم ترکیب کنیم.
“یادگیری برای تعویق” (LtD): پارادایم غالب و محدودیتهای پنهان آن
تا به امروز، یکی از محبوبترین رویکردها برای مدیریت این همکاری، چارچوبی به نام “یادگیری برای تعویق” (Learning to Defer – LtD) بوده است. این ایده در ظاهر بسیار منطقی و کارآمد به نظر میرسد.
“یادگیری برای تعویق” چگونه کار میکند؟
در چارچوب LtD، یک مدل یادگیری ماشین با یک مکانیزم انتخابگر (selector) همراه میشود. این سیستم برای هر نمونه ورودی (مثلاً اطلاعات یک بیمار) دو گزینه دارد:
✨ تصمیم گیری ✨
مدل با اطمینان کافی، خود به پیشبینی نهایی میپردازد (مثلاً تشخیص بیماری).
✨ تعویق✨
اگر مدل در مورد یک نمونه خاص عدم قطعیت بالایی داشته باشد، تصمیمگیری را به طور کامل به یک متخصص انسانی واگذار میکند.
این رویکرد، سیستمهای تطبیقپذیرتری ایجاد میکند، به ویژه در سناریوهایی که تخصص انسانی میتواند پیشبینیهای الگوریتمی را تکمیل کند. اما آیا این مدل همکاری، بهترین شکل ممکن است؟
چرا واگذاری کامل تصمیم همیشه بهینه نیست؟
پژوهشگران نشان دادهاند که چارچوب LtD، با وجود کاراییاش، دو نقص اساسی دارد که آن را از رسیدن به عملکرد بهینه باز میدارد:
🌤️ محدود کردن بازخورد انسانی:
LtD فرض میکند که تنها ورودی ارزشمند از سوی متخصص، پیشبینی نهایی اوست. این رویکرد، سایر اشکال بازخورد غنی مانند حاشیهنویسی روی مفاهیم، توصیف ویژگیهای جزئی یا حتی بیان میزان عدم قطعیت متخصص را نادیده میگیرد.
🌤️ نگاه صفر و یکی به تصمیمگیری:
LtD انسان و ماشین را به عنوان دو تصمیمگیرنده کاملاً مجزا و انحصاری در نظر میگیرد. این نگاه “یا من یا تو”، فرصت همافزایی و ترکیب اطلاعات مکمل را از بین میبرد و اغلب منجر به پدیدهای به نام کمآموزش سیستماتیک (systematic underfitting) میشود، جایی که اطلاعات ارزشمند به سادگی دور ریخته میشوند.
مثالی گویا: وقتی اطلاعات مکمل نادیده گرفته میشود
💎برای درک بهتر این محدودیت، سناریوی سادهای را در نظر بگیرید. فرض کنید برای تشخیص یک بیماری از بین چهار حالت ممکن (y ∈ {0, 1, 2, 3})، دو ویژگی باینری x₁ و x₂ وجود دارد. هر ترکیب منحصربهفرد از این دو ویژگی، به طور قطعی یکی از چهار حالت بیماری را مشخص میکند.
- مدل هوش مصنوعی فقط به ویژگی x₁ (مثلاً یک سیگنال پزشکی پیچیده) دسترسی دارد.
- متخصص انسانی فقط به ویژگی x₂ (مثلاً تاریخچه شفاهی بیمار) دسترسی دارد.
در این حالت، نه مدل و نه متخصص به تنهایی نمیتوانند با دقت بالاتر از ۵۰٪ بیماری را تشخیص دهند. یک سیستم LtD، که فقط میتواند بین پیشبینی مدل (بر اساس x₁) و پیشبینی متخصص (بر اساس x₂) یکی را انتخاب کند، هرگز به دقت کامل نخواهد رسید. این سیستم از ترکیب اطلاعات مکمل موجود در x₁ و x₂ عاجز است. اما سیستمی که بتواند هر دو ویژگی را با هم ادغام کند، میتواند به دقت ۱۰۰٪ دست یابد. این دقیقاً همان جایی است که “یادگیری برای پرسیدن” وارد میدان میشود.🌿
🌷 معرفی چارچوب انقلابی “یادگیری برای پرسیدن” (LtA)
چارچوب “یادگیری برای پرسیدن” (LtA) پاسخی به محدودیتهای LtD است. این رویکرد به جای بهینهسازی برای “واگذاری” تصمیم، بر روی دو سؤال کلیدی تمرکز میکند: چه زمانی باید از متخصص بازخورد درخواست کرد و چگونه باید این بازخورد را در فرآیند تصمیمگیری مدل ادغام کرد.
تغییر پارادایم: از “چه کسی تصمیم بگیرد؟” به “چه زمانی بپرسیم و چگونه ادغام کنیم؟”
LtA این فرض را که انسان و ماشین باید به طور انحصاری عمل کنند، کنار میگذارد. در این چارچوب، هدف این است که یک همکاری همافزایانه ایجاد شود که در آن هر دو عامل به طور همزمان در تصمیمگیری مشارکت داشته باشند. این مدل نه تنها پتانسیل عملکرد مکمل را به رسمیت میشناسد، بلکه امکان همکاریهای سینرژیک را نیز فراهم میکند.
معماری دوگانه LtA: مدل استاندارد در برابر مدل غنیشده
برای دستیابی به این هدف، LtA بر یک معماری دو قسمتی استوار است:
مدل استاندارد (f)
یک طبقهبند یادگیری ماشین معمولی که تنها بر اساس ویژگیهای ورودی اولیه (x) پیشبینی میکند.
این مدل زمانی استفاده میشود که نیازی به مداخله انسانی نباشد.
مدل غنیشده (gψ)
یک مدل پیشرفتهتر که علاوه بر ویژگیهای اولیه (x)، ورودیهای اضافی از متخصص انسانی (h) را نیز دریافت و پردازش میکند. این ورودی انسانی میتواند هر چیزی باشد: از پیشبینی نهایی متخصص (مانند LtD) گرفته تا ویژگیهای اضافی، سطح عدم قطعیت، یا حتی یک گزارش متنی.
یک استراتژی انتخاب (hα) نیز وجود دارد که تعیین میکند برای هر نمونه، آیا باید از مدل استاندارد استفاده کرد یا با صرف هزینه (زمان و انرژی متخصص)، بازخورد انسانی را درخواست و از مدل غنیشده بهره برد.
استراتژی بهینه برای پرسش: علم پشت تصمیمگیری هوشمند
یکی از دستاوردهای کلیدی چارچوب LtA، ارائه یک مبنای نظری محکم برای تصمیمگیری در مورد زمان پرسش از متخصص است. این تصمیم دیگر یک حدس و گمان نیست، بلکه یک محاسبه بهینه بر اساس ریسک و هزینه است.
چه زمانی پرسیدن از یک متخصص ارزشش را دارد؟
بر اساس قضیه ۱ در مقاله اصلی، استراتژی انتخاب بهینه (hα*) تحت یک محدودیت بودجه (B، یعنی حداکثر درصدی از موارد که میتوان از متخصص کمک گرفت) به شکل زیر است:“تنها زمانی از مدل غنیشده استفاده کن که کاهش مورد انتظار در خطای مدل، از یک آستانه مشخص (TB*) بیشتر باشد.”
به زبان سادهتر، سیستم به طور خودکار محاسبه میکند که آیا اطلاعات اضافی که متخصص فراهم میکند، به اندازهای ارزشمند است که هزینه درخواست آن را توجیه کند یا خیر. این آستانه به طور خودکار بر اساس بودجه تعیین شده تنظیم میشود. این رویکرد تضمین میکند که منابع ارزشمند انسانی (زمان متخصصان) تنها در مواردی به کار گرفته میشود که بیشترین تأثیر را بر بهبود عملکرد کلی سیستم دارند.
فراتر از پیشبینی: انواع جدید بازخورد انسانی
زیبایی LtA در انعطافپذیری آن در تعریف “بازخورد انسانی” (h) نهفته است. برخلاف LtD که بازخورد را به یک برچسب پیشبینی محدود میکند، LtA میتواند از انواع غنیتری از اطلاعات بهره ببرد، مانند:
پیشبینیهای عدم قطعیت
متخصص میتواند میزان اطمینان خود به تشخیص را اعلام کند.
ویژگیهای اضافی
یک پزشک میتواند نتایج یک آزمایش تکمیلی را که برای مدل در دسترس نیست، وارد کند.
حاشیهنویسیهای مفهومی
یک رادیولوژیست میتواند ناحیه مشکوک در یک تصویر پزشکی را مشخص کند.
گزارشهای بدون ساختار
کل گزارش پزشکی میتواند به عنوان ورودی برای مدل غنیشده استفاده شود.
این انعطافپذیری، درهای جدیدی را به روی طراحی سیستمهای هوشمند تعاملی باز میکند.
چگونه مدلهای “یادگیری برای پرسیدن” را در عمل پیادهسازی کنیم؟
پیادهسازی یک سیستم LtA نیازمند آموزش سه مؤلفه است: مدل استاندارد (f)، مدل غنیشده (gψ) و استراتژی انتخاب (hα). پژوهشگران دو رویکرد عملی برای این کار پیشنهاد کردهاند:
رویکرد متوالی (LtA-Seq): سادگی در برابر خطر کمآموزش
در این رویکرد، فرآیند آموزش به دو مرحله تقسیم میشود:
- ابتدا، مدل غنیشده (gψ) با استفاده از تمام دادههایی که بازخورد انسانی دارند، آموزش داده میشود.
- سپس، با ثابت در نظر گرفتن مدل gψ، مدل استاندارد (f) و انتخابگر (hα) با استفاده از تکنیکهای موجود در ادبیات LtD آموزش داده میشوند.
مزیت این روش، سادگی و بهرهگیری از ضمانتهای نظری موجود در چارچوب LtD است. اما یک نقطه ضعف مهم دارد: این روش مستعد کمآموزش (underfitting) است. از آنجایی که مدل gψ ابتدا و بدون در نظر گرفتن هزینه پرسش آموزش میبیند، سیستم ممکن است بیش از حد به آن تکیه کند و در نتیجه، مدل استاندارد (f) به خوبی آموزش نبیند.
رویکرد مشترک (LtA-Joint): بهینهسازی یکپارچه برای عملکرد حداکثری
برای غلبه بر مشکل کمآموزش، رویکرد دوم پیشنهاد میشود که در آن هر سه مؤلفه (f، gψ و hα) به طور همزمان و مشترک بهینهسازی میشوند. برای این کار، پژوهشگران توابع زیان جایگزین (surrogate loss functions) جدیدی طراحی کردهاند که دارای ضمانتهای سازگاری نظری (realizable-consistency) هستند.
این رویکرد مشترک به طور طبیعی سیستم را به سمت یک تعادل بهینه سوق میدهد. فرآیند آموزش مشترک مانند یک تنظیمکننده (regularizer) عمل میکند و باعث میشود سیستم تنها زمانی از متخصص درخواست کمک کند که واقعاً سودمند باشد. این امر از اتکای بیش از حد به مدل غنیشده جلوگیری کرده و عملکرد قویتری را در تمام سطوح بودجه تضمین میکند.
نتایج تجربی: LtA در آزمون واقعیت
اثربخشی چارچوب LtA بر روی دادههای شبیهسازیشده و همچنین یک مجموعه داده واقعی در دنیای پزشکی مورد ارزیابی قرار گرفته است تا به پرسشهای کلیدی زیر پاسخ داده شود:
- Q1: عملکرد LtA در مقایسه با LtD چگونه است؟
- Q2: نوع بازخورد متخصص چقدر بر عملکرد تأثیر میگذارد؟
- Q3: آیا میتوان با تنظیم هزینه، مشکل کمآموزش را کاهش داد؟
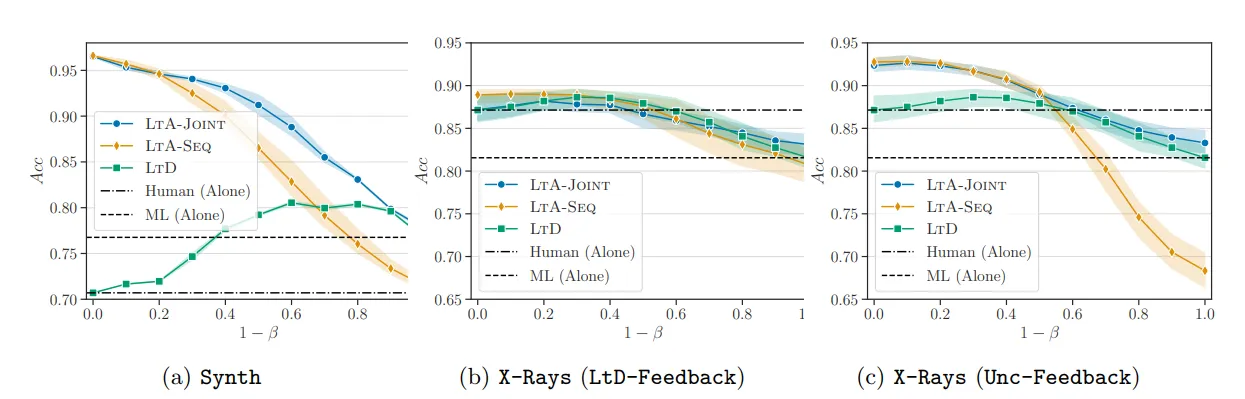
برتری مشهود بر “یادگیری برای تعویق” در سناریوهای مختلف
نتایج روی دادههای شبیهسازیشده (Synth) بسیار واضح بود. هر دو استراتژی LtA (متوالی و مشترک) به طور قابل توجهی از LtD بهتر عمل کردند، به ویژه زمانی که بودجه برای پرسش از متخصص محدود بود. به طور خاص، LtA-Joint به طور مداوم در تمام سطوح بودجه از LtD پیشی گرفت و عملکرد مکمل قویتری را به نمایش گذاشت؛ یعنی دقت آن از دقت هر یک از عوامل (ماشین یا متخصص) به تنهایی، فراتر رفت.
مطالعه موردی: تشخیص بیماری از روی تصاویر رادیولوژی قفسه سینه
برای آزمون در دنیای واقعی، از مجموعه داده تصاویر رادیولوژی قفسه سینه NIH Google Chest X-ray استفاده شد. در این مجموعه، هر تصویر توسط چندین پزشک برای چهار بیماری مختلف بررسی شده است.
سناریوی اول (بازخورد استاندارد LtD): زمانی که بازخورد متخصص صرفاً یک پیشبینی باینری (سالم یا بیمار) بود، عملکرد مدلهای LtA مشابه LtD بود. در این حالت، عملکرد مکمل محدود بود و سیستمها به سختی میتوانستند از دقت متخصص به تنهایی بهتر عمل کنند.
سناریوی دوم (بازخورد غنی): اما زمانی که بازخورد متخصص شامل اطلاعات غنیتری بود (در اینجا، احتمال اجماع پزشکان در مورد هر بیماری، که نشاندهنده عدم قطعیت بود)، نتایج به طور چشمگیری تغییر کرد.
قدرت بازخورد غنی: تأثیر اطلاعات مرتبط با عدم قطعیت
با استفاده از بازخورد غنی (Unc-Feedback)، هر دو مدل LtA-Seq و LtA-Joint به طور قابل توجهی از LtD بهتر عمل کردند و در برخی موارد تا ۵٪ بهبود دقت را نشان دادند. این نتیجه تأیید میکند که بزرگترین مزیت LtA، توانایی آن در بهرهبرداری از اطلاعاتی است که فراتر از یک پیشبینی ساده هستند. با استفاده از این اطلاعات، سیستمهای LtA توانستند به عملکرد مکمل واقعی دست یابند و از عملکرد انسان و ماشین به تنهایی پیشی بگیرند.
آزمایشها همچنین نشان دادند که افزایش هزینه پرسش از متخصص (پارامتر d) میتواند به کاهش مشکل کمآموزش در مدل LtA-Seq کمک کند و عملکرد آن را به مدل قدرتمندتر LtA-Joint نزدیکتر سازد.
تفاوت بنیادین LtA با LtD
| ویژگی | LtD (یادگیری برای واگذاری) | LtA (یادگیری برای پرسیدن) |
|---|---|---|
| نقش انسان | تصمیمگیرندهٔ نهایی | منبع بازخورد و دادهٔ تکمیلی |
| نوع همکاری | جایگزینی متقابل | همافزایی و ترکیب اطلاعات |
| نوع دادهٔ انسانی | پیشبینی (label) | بازخورد متنوع، ویژگی، عدمقطعیت و … |
| هزینهٔ تعامل | وابسته به دفعات واگذاری | وابسته به دفعات پرسش |
| انعطافپذیری | محدود | بالا و قابل تنظیم با بودجهٔ β |
پیامدهای “یادگیری برای پرسیدن” برای آینده هوش مصنوعی
چارچوب “یادگیری برای پرسیدن” فقط یک پیشرفت فنی نیست؛ بلکه یک تغییر نگرش در مورد چگونگی تعامل انسان و ماشین است. این رویکرد پیامدهای گستردهای برای طراحی نسل بعدی سیستمهای هوشمند دارد.
کاربردها در حوزههای حساس: پزشکی، مالی و فراتر از آن
پزشکی
یک سیستم LtA میتواند از یک رادیولوژیست بخواهد تا یک ناحیه مشکوک را در تصویر مشخص کند، به جای اینکه کل تشخیص را به او واگذار کند. این کار باعث صرفهجویی در زمان و افزایش دقت میشود.
تشخیص تقلب مالی
یک الگوریتم میتواند تراکنشهای مشکوک را شناسایی کرده و از یک تحلیلگر انسانی بخواهد تا اطلاعات زمینهای بیشتری (مثلاً تاریخچه مشتری) را ارائه دهد تا تصمیم نهایی با دقت بالاتری گرفته شود.
تعدیل محتوا
به جای اینکه ناظران انسانی هر پست پرچمگذاریشده را از ابتدا بررسی کنند، سیستم میتواند از آنها سؤالات هدفمندی در مورد جنبههای خاص محتوا (مانند لحن، زمینه فرهنگی و غیره) بپرسد.
این چارچوب به ما اجازه میدهد تا سیستمهایی بسازیم که نه تنها دقیقتر هستند، بلکه از منابع انسانی گرانبها نیز بهینهتر استفاده میکنند.
نتیجهگیری: به سوی همافزایی واقعی بین انسان و هوش مصنوعی
“یادگیری برای تعویق” (LtD) گام مهمی در مسیر همکاری انسان و ماشین بود، اما با محدود کردن تعامل به یک انتخاب “یا این یا آن”، پتانسیل کامل این همکاری را نادیده میگرفت. چارچوب “یادگیری برای پرسیدن” (LtA) با تغییر سؤال از “چه کسی تصمیم میگیرد؟” به “چه زمانی باید پرسید و چگونه باید اطلاعات را ادغام کرد؟”، این محدودیت را از میان برمیدارد.
LtA با ارائه یک مبنای نظری قوی، معماری انعطافپذیر و نتایج تجربی قانعکننده، نشان میدهد که آینده همکاری انسان و هوش مصنوعی در یک گفتگوی هوشمندانه نهفته است، نه یک واگذاری ساده. این چارچوب یک پایه قدرتمندتر و انعطافپذیرتر برای ساخت سیستمهایی فراهم میکند که در آن انسان و ماشین نه به عنوان رقیب، بلکه به عنوان شرکای واقعی برای رسیدن به بهترین نتایج ممکن با یکدیگر همکاری میکنند. این، همان همافزایی است که آینده هوش مصنوعی را شکل خواهد داد.