عامل زبانی (LLM) به جای انسان: تنظیم خودکار نرخ یادگیری در آموزش
مقدمه: چرا آموزش هوش مصنوعی به بازنگری نیاز دارد؟
فرآیند آموزش شبکههای عصبی در سالهای اخیر دگرگونیهای شگرفی را تجربه کرده است. با وجود پیشرفتهای چشمگیر در سختافزار و الگوریتمها، هنوز بیشتر مدلهای هوش مصنوعی به شیوهای ایستا و از پیشتعریفشده آموزش میبینند. در این روش، پژوهشگر مجموعهای از ابرپارامترها (مانند نرخ یادگیری، تعداد لایهها و اندازهی دستهها) را تعیین میکند و سپس مدل بدون تعامل انسانی تا پایان آموزش اجرا میشود.اما این روش محدودیتهایی دارد:
- اگر در میانهی مسیر، مدل دچار ناپایداری یا نوسان در تابع هزینه شود، پژوهشگر معمولاً چارهای جز توقف کامل و شروع دوباره ندارد.
- منابع محاسباتی بهصورت قابلتوجهی هدر میروند.
- مدلها نمیتوانند خود را با تغییرات دادههای واقعی یا نیازهای کاربر تطبیق دهند.
در پاسخ به این چالشها، رویکردی نوین با عنوان آموزش تعاملی (Interactive Training) معرفی شده است؛ روشی که با الهام از مفهوم بازخورد زنده، امکان کنترل و اصلاح فرآیند آموزش در لحظه را فراهم میسازد.
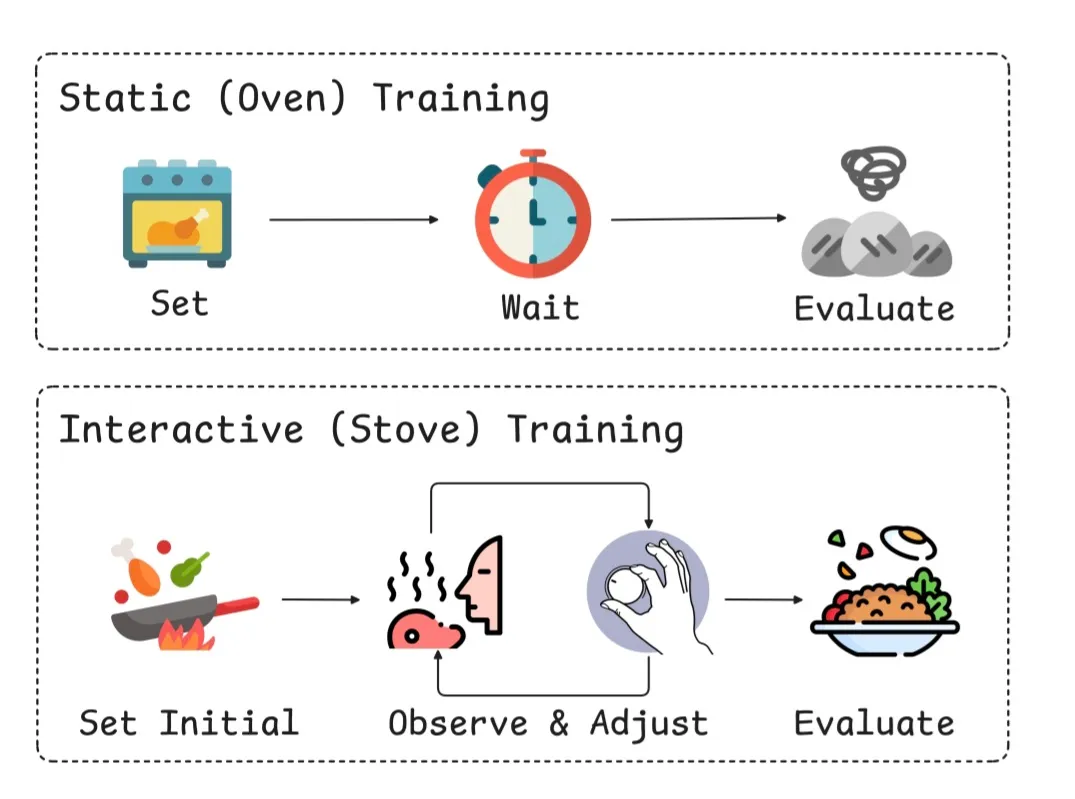
شکل ۱: آموزش ایستا مانند پختن کیک در فر بسته است: پارامترها تا پایان ثابت هستند. آموزش تعاملی مانند آشپزی روی اجاق است: میتوانید در لحظه تنظیم کنید.
آموزش تعاملی چیست؟
تعریف کلی
آموزش تعاملی نوعی چارچوب پویا برای بهینهسازی شبکههای عصبی است که به انسانها یا عاملهای هوش مصنوعی اجازه میدهد در حین آموزش، پارامترها و دادهها را تغییر دهند.
بهعبارت ساده، اگر آموزش سنتی را به پختن کیک در یک فر بسته تشبیه کنیم، آموزش تعاملی مانند پختوپز روی اجاق است؛ جایی که آشپز میتواند در هر لحظه دما، ادویه یا مواد را تنظیم کند.
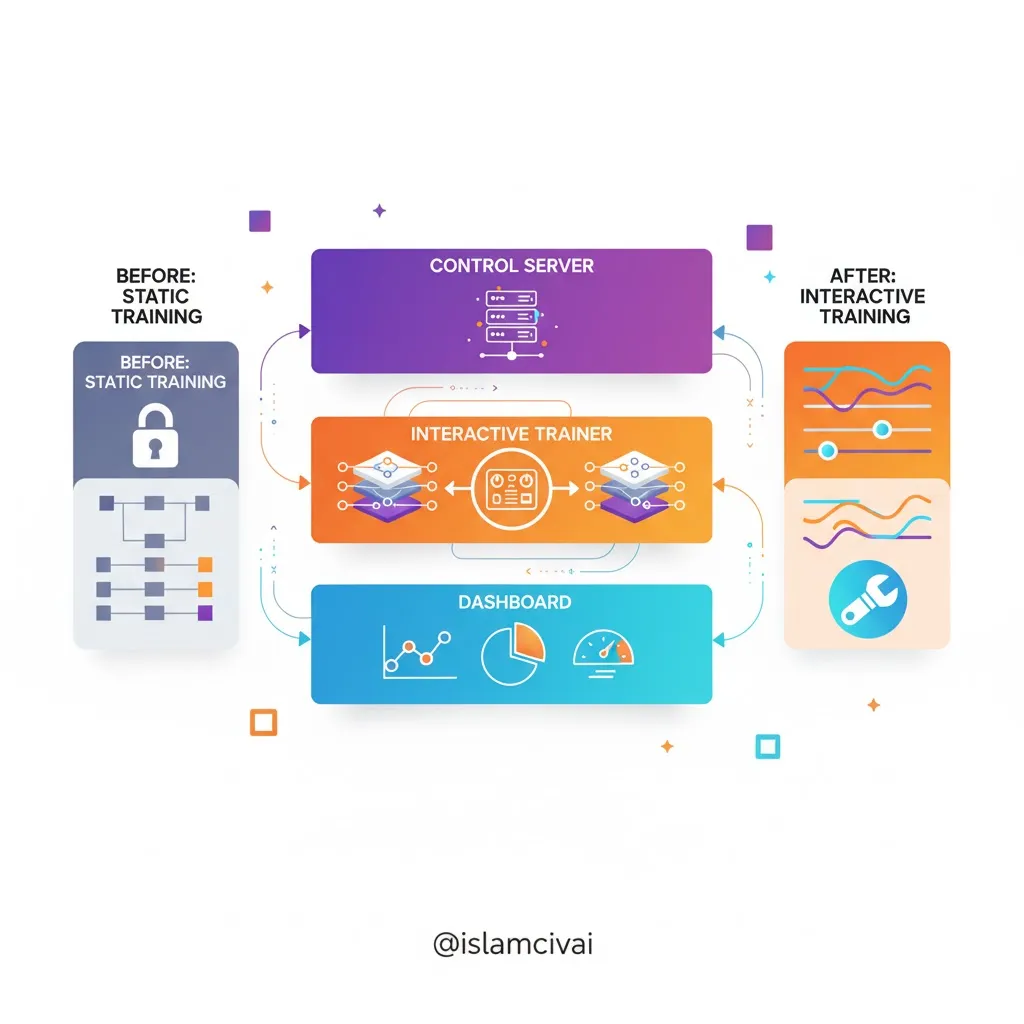
ساختار کلی سیستم آموزش تعاملی
۱. سرور کنترل (Control Server)
این بخش، نقش مغز مرکزی سامانه را ایفا میکند. تمام دستورات کاربران یا عاملهای هوشمند از این طریق به موتور آموزش ارسال میشود.
سرور کنترل وظیفه دارد:
- دستورات مربوط به تغییر نرخ یادگیری یا ذخیرهی نقاط بازیابی (checkpoint) را پردازش کند.
- وضعیت آموزش را در قالب گزارشهای بلادرنگ برای کاربران ارسال نماید.
- تاریخچهی تمامی مداخلات را ثبت کند تا قابلیت بازتولید آزمایشها حفظ شود.
شکل ۳: داشبورد → سرور کنترل → مربی تعاملی. ارتباط دوطرفه از طریق REST API و WebSocket.
۲. مربی تعاملی (Interactive Trainer)
این بخش، نسخهی توسعهیافتهای از کلاس Trainer در کتابخانهی Hugging Face Transformers است. مربی تعاملی دارای تابعهای بازخوان (Callback) است که به محض دریافت فرمان، پارامترها را در گام بعدی گرادیان بهروزرسانی میکند.نمونهای از این توابع عبارتاند از:
- InteractiveCallback برای تنظیم بلادرنگ نرخ یادگیری
- CheckpointCallback برای ذخیره و بارگذاری ایستگاههای آموزشی
- LoggingCallback برای ارسال معیارها به سرور
- RunPauseCallback برای توقف یا ادامهی آموزش

شکل ۴: فقط ۳ خط کد برای تبدیل Trainer معمولی به InteractiveTrainer!
۳. داشبورد تعاملی (Frontend Dashboard)
رابط کاربری وب، به کاربران اجازه میدهد تا در لحظه تغییرات را مشاهده و کنترل کنند. این داشبورد با استفاده از فریمورک React و TypeScript توسعه یافته و از طریق ارتباط WebSocket با سرور کنترل، بهروزرسانیهای بلادرنگ را دریافت میکند. در این داشبورد، نمودارهایی از تابع هزینه، گرادیانها، نرخ یادگیری، نرم گرادیان و پارامترهای بهینهساز بهصورت پویا نمایش داده میشود. کاربر میتواند با چند کلیک ساده، نرخ یادگیری را تغییر دهد، مدل را به نسخهای قبلی بازگرداند، دادههای آموزشی را بهروزرسانی کند یا حتی فرآیند آموزش را موقتاً متوقف و از سر گیرد.
برخلاف ابزارهای نظارتی سنتی که تنها نمایشدهندهی معیارها هستند، این داشبورد از ارتباط دوطرفه پشتیبانی میکند: کاربر نهتنها وضعیت آموزش را میبیند، بلکه میتواند دستورات کنترلی را مستقیماً از طریق پنلهای دستهبندیشده (Optimizer، Model، Checkpoint، Dataset) ارسال کند. این دستورات از طریق APIهای RESTful به سرور کنترل منتقل شده و در گام بعدی گرادیان اعمال میشوند. همچنین، داشبورد از نمایش مسیرهای شاخهای آموزش (branched training trajectories) پشتیبانی میکند؛ به این معنا که کاربر میتواند چندین مسیر آزمایشی از یک نقطهی مشترک را مشاهده و مقایسه کند.
در پایین داشبورد، یک کنسول لاگ تعبیه شده است که تاریخچهی دستورات ارسالی، پاسخهای تأیید از فرآیند آموزش و هشدارهای حیاتی (مانند «تشخیص سرریز گرادیان») را نمایش میدهد.
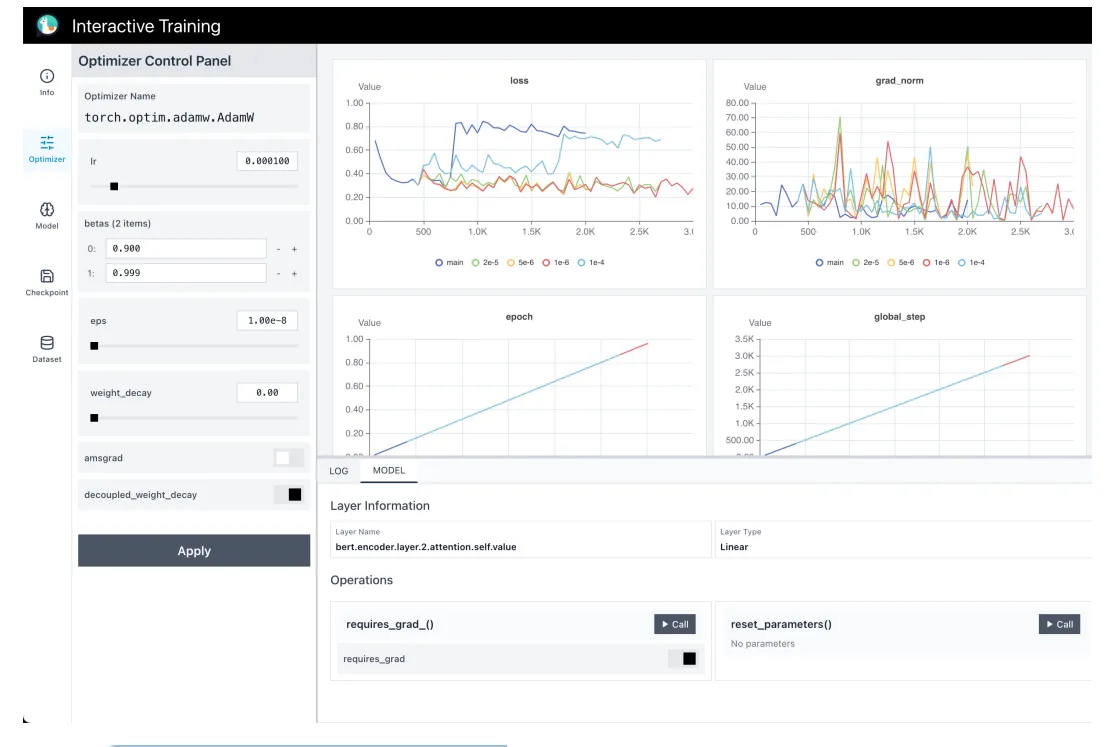 شکل ۲: پنل چپ: کنترل (نرخ یادگیری، چکپوینت، داده). پنل راست: نمودارهای بلادرنگ.
شکل ۲: پنل چپ: کنترل (نرخ یادگیری، چکپوینت، داده). پنل راست: نمودارهای بلادرنگ.
مزایای کلیدی آموزش تعاملی
۱. پویایی در مواجهه با ناپایداریها
در آموزش ایستا، بروز نوسانات یا افت عملکرد به معنی شکست آزمایش و از دست رفتن منابع محاسباتی است. اما در آموزش تعاملی، پژوهشگر میتواند در لحظه واکنش نشان دهد، نرخ یادگیری را کاهش دهد، یا به چکپوینت قبلی بازگردد و مسیر آموزش را اصلاح کند — همانطور که در مطالعه اول (بخش ۳.۱) با تنظیم دستی نرخ یادگیری در GPT-2 مشاهده شد.
۲. صرفهجویی در زمان و منابع
بهجای توقف کامل و شروع دوباره که در کلاسترهای مدیریتشده صفهای طولانی ایجاد میکند، تنها کافی است پارامترهای مؤثر مانند نرخ یادگیری یا آستانهی کلیپ گرادیان تغییر یابند. این موضوع منجر به کاهش چشمگیر هزینهی محاسباتی، مصرف انرژی و زمان انتظار در صف پردازش میشود.
۳. یادگیری تطبیقی بر پایهی دادههای واقعی
آموزش تعاملی این امکان را میدهد که دادههای تازه از محیط واقعی بهصورت تدریجی به مدل تزریق شوند؛ بهویژه در کاربردهایی مانند گفتوگوگرهای هوشمند یا سیستمهای تولید تصویر که دائماً با دادههای جدید روبهرو هستند. در مطالعه سوم (بخش ۳.۳)، مدل NeuralOS با دریافت ۷۴۶ تعامل واقعی کاربر طی ۱۴ روز، توانست رفتارهای پیچیده مانند باز کردن Firefox را بهدرستی پیشبینی کند — بدون نیاز به آموزش مجدد از ابتدا.
۴. تلفیق هوش انسانی و مصنوعی در آموزش
ترکیب تجربهی انسان با قدرت پردازش عاملهای زبانی بزرگ (LLM) باعث میشود فرآیند آموزش هم دقیقتر و هم خودکارتر شود. در مطالعه دوم (بخش ۳.۲)، یک عامل مبتنی بر o4-mini با تحلیل لاگهای آموزشی، توانست نرخ یادگیری بیش از حد بالا (5×10⁻³) را بهصورت خودکار کاهش دهد و از ناپایداری جلوگیری کند — گامی بهسوی آموزش کاملاً خودکار.
نمونههای عملی از آموزش تعاملی
مطالعهی موردی اول: انسان در حلقهی آموزش (Human-in-the-Loop)
در این آزمایش، پژوهشگران مدل GPT-2 را بر روی مجموعهدادهی Wikitext-2 آموزش دادند. در نسخهی ایستا، نرخ یادگیری از ۱×۱۰⁻⁵ بهصورت خطی تا صفر کاهش یافت. در نسخهی تعاملی، متخصص انسانی هنگام مشاهدهی نوسان در تابع هزینه (شکل ۵a)، نرخ یادگیری را بهصورت بلادرنگ کاهش داد. نتیجه؟ کاهش چشمگیر خطای اعتبارسنجی (تا ۰.۳ واحد) و همگرایی سریعتر نسبت به آموزش ایستا (شکل ۵b).
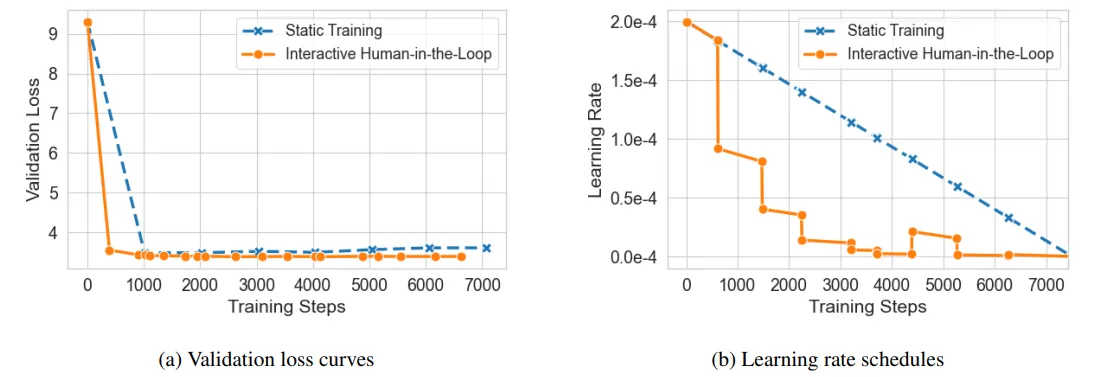 شکل ۵: (a) ضرر اعتبارسنجی، (b) نرخ یادگیری واقعی در طول آموزش.
شکل ۵: (a) ضرر اعتبارسنجی، (b) نرخ یادگیری واقعی در طول آموزش.
مطالعهی دوم: مداخلهی خودکار توسط مدل زبانی بزرگ (LLM-in-the-Loop)
در گامی پیشرفتهتر، نقش انسان به یک عامل زبانی هوشمند (o4-mini از OpenAI) واگذار شد. این عامل با تحلیل گزارشهای آموزشی — شامل ضرایب یادگیری، ضرایب ضرر و گامهای اخیر — و با استفاده از پرامپت JSON (شکل ۷)، تصمیم میگرفت که نرخ یادگیری را دوبرابر، نصف یا ثابت نگه دارد. بهاینترتیب، مدل توانست از ناپایداری اولیه با نرخ ۵×۱۰⁻³ (شکل ۶a) نجات یابد و به همگرایی مطلوب برسد (شکل ۶b) — بدون دخالت انسانی.
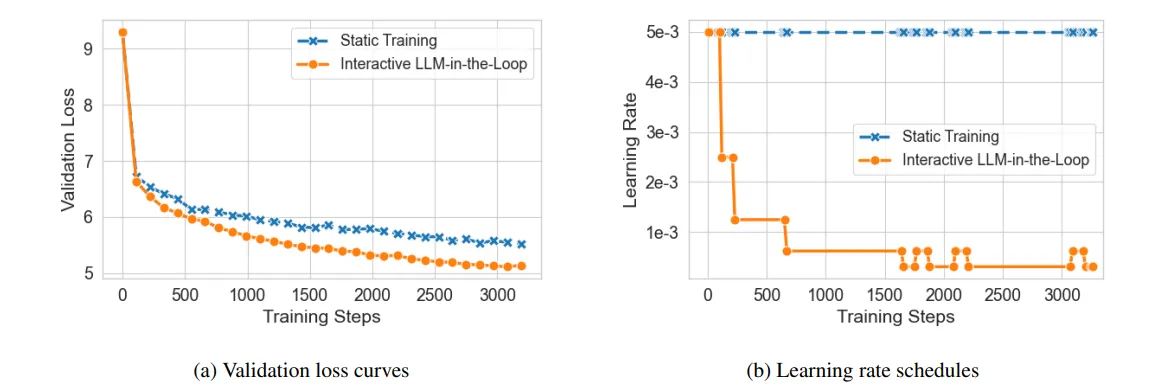 شکل ۶: (a) ضرر اعتبارسنجی، (b) مسیر نرخ یادگیری.
شکل ۶: (a) ضرر اعتبارسنجی، (b) مسیر نرخ یادگیری.
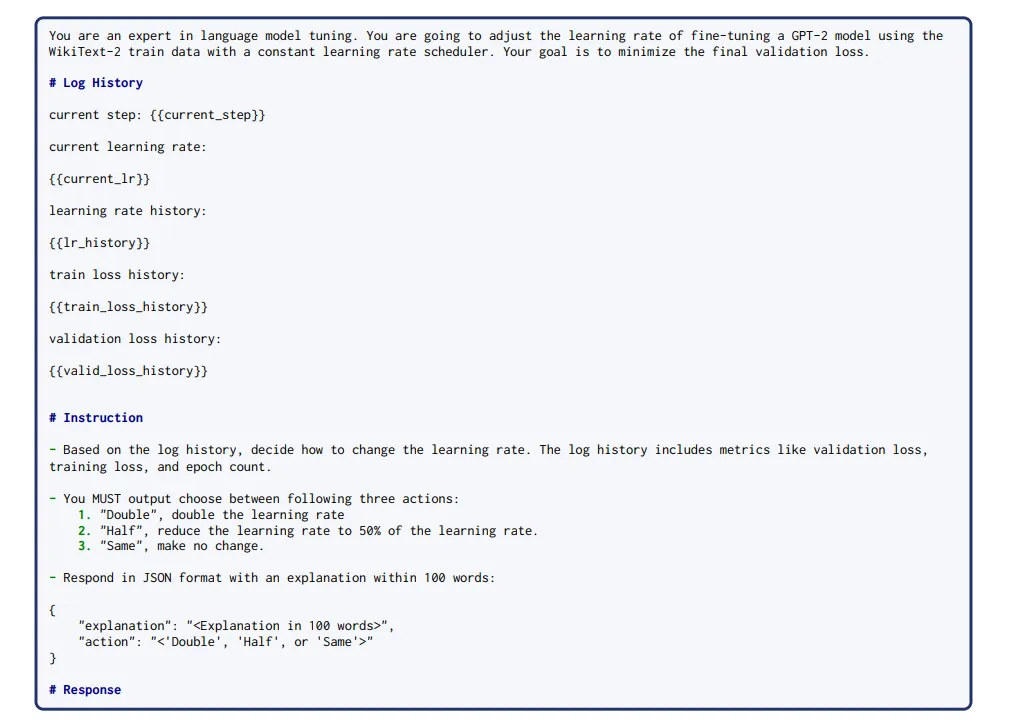 شکل ۷: پرامپت JSON برای عامل o4-mini.
شکل ۷: پرامپت JSON برای عامل o4-mini.
مطالعهی سوم: بهروزرسانی دادههای آموزشی در زمان واقعی
در پروژهی NeuralOS، مدل مبتنی بر انتشار (Diffusion Model) پس از استقرار در وب[](https://neural-os.com)، دادههای واقعی کاربران را دریافت و بهصورت خودکار در فرآیند آموزش وارد کرد. طی ۱۴ روز، ۷۴۶ دنبالهی تعاملی (۸۸ هزار انتقال فریم) جمعآوری شد. این کار سبب شد که مدل، عملکرد بهتری در شبیهسازی رفتار واقعی کاربران — بهویژه در وظایفی مانند باز کردن مرورگر Firefox یا ایجاد پوشههای جدید (شکل ۸) — نشان دهد، بدون نیاز به آموزش مجدد.
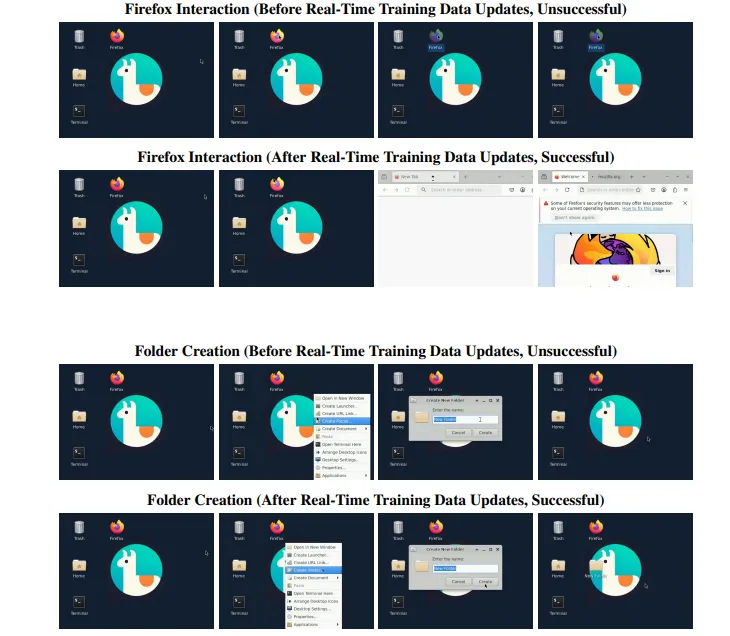 شکل ۸: مقایسه قبل و بعد از بهروزرسانی دادههای واقعی.
شکل ۸: مقایسه قبل و بعد از بهروزرسانی دادههای واقعی.
تفاوت آموزش تعاملی با یادگیری فعال (Active Learning)
در یادگیری فعال، مدل تنها از انسان برای برچسبگذاری دادهها کمک میگیرد. اما در آموزش تعاملی، کنترل مستقیم فرآیند آموزش نیز در اختیار انسان یا عامل هوشمند است. به عبارت دیگر، در یادگیری فعال انسان “منبع داده” است؛ ولی در آموزش تعاملی، او “راهنمای فرآیند یادگیری” محسوب میشود.
چالشها و محدودیتها
۱. مسئلهی بازتولید نتایج
از آنجا که هر کارشناس ممکن است مداخلات متفاوتی انجام دهد، نتایج نهایی میتواند متغیر باشد. برای مثال، مدل OPT از متا بهدلیل خرابی سختافزار، حداقل ۳۵ بار بهصورت دستی ریاستارت شد (Zhang et al., 2022). برای رفع این مشکل، سامانهی آموزش تعاملی تمامی دستورات را در قالب فایلهای JSON با فیلدهای uuid، time و status ثبت میکند تا امکان تکرار دقیق آزمایش و بازتولید نتایج وجود داشته باشد.
۲. نیاز به مهارت تخصصی
برای استفادهی مؤثر از این سیستم، کاربر باید دانش کافی دربارهی رفتار گرادیانها، نرخ یادگیری، نرم گرادیان و پویایی مدلها داشته باشد. در حال حاضر، تشخیص زمان مناسب برای کاهش نرخ یادگیری یا بازگشت به چکپوینت، نیازمند تجربه است. هرچند با پیشرفت عاملهای هوشمند مانند o4-mini (مطالعه دوم)، انتظار میرود این وابستگی به تخصص انسانی بهتدریج کاهش یابد.
۳. کمبود داده برای آموزش عاملهای مداخلهگر
چون این حوزه نوظهور است، مدلهای زبانی هنوز تجربهی کافی در تصمیمگیری بلادرنگ در فرآیند آموزش ندارند. عاملهای LLM مانند o4-mini با پرامپتهای عمومی آموزش دیدهاند و فاقد دادههای تخصصی از لاگهای آموزشی واقعی هستند. این محدودیت، دقت مداخلات خودکار را کاهش میدهد.
آیندهی آموزش تعاملی: از انسان تا عامل خودمختار
۱. پایش سلامت آموزش
در آینده، میتوان برای مدلها شاخصهایی مشابه «علائم حیاتی» طراحی کرد—مثلاً انحراف معیار حالات پنهان برای تشخیص نرونهای غیرفعال (Ioffe and Szegedy, 2015) یا تحلیلهای پیچیدهتر مانند مدلسازی دینامیک آموزش (Hu et al., 2023). این شاخصها میتوانند بهصورت خودکار هشدارهایی مانند «نرونهای مرده شناسایی شد» در داشبورد نمایش دهند.
۲. یادگیری دادهمحور پویا
عاملهای هوشمند قادر خواهند بود با ارزیابی چکپوینتهای میانی، ضعفهای مدل را شناسایی کنند، سپس دادههای هدفمند مصنوعی تولید کرده یا وزن مخلوط دادههای موجود را تنظیم کنند (Albalak et al., 2023). این رویکرد، مشابه مطالعه سوم در NeuralOS، میتواند مدل را بهصورت مداوم با نیازهای واقعی کاربران هماهنگ کند.
۳. عاملهای خودکار مداخلهگر
نسل بعدی آموزش تعاملی شامل عاملهایی است که بدون دخالت انسان، نوسانات را تشخیص داده و اصلاحات لازم را اعمال میکنند—نوعی «دستیار آموزشی خودکار». این عاملها میتوانند با آموزش تخصصی روی لاگهای واقعی (مانند o4-mini در مطالعه دوم)، نرخ یادگیری را تنظیم کنند، گرادیانها را کلیپ کنند، یا حتی آموزش را متوقف و از سر گیرند.
کاربردهای بالقوه در صنعت
مدلهای زبانی بزرگ (LLMs): بهینهسازی دقیق نرخ یادگیری برای جلوگیری از فراموشی تدریجی.
مدلهای تصویری: تنظیم پویا در فرآیند تولید تصاویر باکیفیتتر.
روباتیک هوشمند: آموزش رباتها با بازخورد انسانی در زمان واقعی.
یادگیری تقویتی (RL): تنظیم پاداشها و سیاستها در حین آموزش برای افزایش پایداری.
نتیجهگیری
آموزش تعاملی، پارادایم تازهای در دنیای یادگیری ماشین است؛ رویکردی که آموزش مدلهای هوش مصنوعی را از یک فرآیند «ایستا و کور» به یک فرآیند پویای بازخوردی تبدیل میکند. همانگونه که مهندسی نرمافزار از مدلهای خطی به شیوهی «توسعهی چابک» تحول یافت، یادگیری ماشین نیز اکنون در آستانهی ورود به عصر آموزش تعاملی و بازخوردمحور است — همانطور که در سه مطالعهی موردی (انسان، LLM و NeuralOS) نشان داده شد. این تحول، نه تنها موجب افزایش کارایی مدلها، کاهش هزینهها و همگرایی سریعتر میشود، بلکه دریچهای به سوی آیندهای میگشاید که در آن، انسان و ماشین همراه با یکدیگر یاد میگیرند، رشد میکنند و بهصورت مداوم بهبود مییابند.