🧠 کشف خودکار مدارهای مکانیزمی در مدلهای زبانی با رویکرد Position-Aware
مدلهای زبانی بزرگ (LLMs) امروز به نقطهای رسیدهاند که توانایی آنها برای درونیسازی الگوهای پیچیده، استدلال چندمرحلهای و رفتارهای وابسته به زمینه بهشدت مورد توجه پژوهشگران قرار گرفته است. اما سؤال اصلی اینجاست:
این مدلها چطور به این نتایج میرسند؟ 🤔
برای پاسخ به این سؤال، حوزهای به نام تفسیرپذیری مکانیکی (Mechanistic Interpretability) شکل گرفته است. یکی از ابزارهای کلیدی این حوزه، کشف مدار (Circuit Discovery) است؛ یعنی یافتن زیرشبکهای از محاسبات که مسئول انجام یک کار خاص در مدل است.
مقالهی اصلی رویکردی نوآورانه ارائه میدهد که این فرآیند را دقیقتر، موقعیتمحور و خودکار میکند. مهمترین چالش: روشهای قبلی معمولاً «موقعیتناآگاه» هستند؛ یعنی فرض میکنند یک جزء مدل در همه موقعیتهای ورودی نقش یکسانی دارد، در حالی که این فرض در عمل صحیح نیست.
🔍 اهمیت موقعیتگرایی در تفسیر مدلهای زبانی
❗ مدلها بسته به موقعیت توکنها رفتار متفاوتی دارند.
مثلاً تعامل هدهای توجه در موقعیتهای اول، میانی و پایانی جمله کاملاً متفاوت است.
این موضوع بهویژه در کارهای زیر اهمیت دارد:
- تشخیص نقش ضمیرها
- مقایسه مقادیر عددی
- استنباط روابط علّی
- بازیابی اطلاعات از زمینه
روشهای قبلی با نادیدهگرفتن موقعیتها:
- کاهش precision
- کاهش recall
- افزایش اندازه مدار
- کاهش faithfulness
⚙️ معرفی روش PEAP: Position-aware Edge Attribution Patching
روش PEAP درواقع نسخهٔ توسعهیافتهٔ Edge Patching محسوب میشود که یک ضعف کلیدی روشهای پیشین را برطرف میکند: ناتوانی در تشخیص اینکه یک لبه در کدام موقعیت اهمیت پیدا میکند. این روش بهجای اینکه اهمیت لبهها را در کل توالی یکجا تجمیع کند، اهمیت هر لبه را برای هر موقعیت بهصورت مستقل اندازهگیری میکند و بنابراین میتواند تشخیص دهد یک ارتباط تنها در یک موقعیت خاص فعال میشود، فقط در یک بازهٔ معنایی نقش دارد یا میان دو موقعیت مجزا عمل میکند. نتیجه این است که مدارهای استخراجشده کوچکتر، دقیقتر، و بسیار نزدیکتر به رفتار واقعی مدل هستند و از خطاهای روشهای تجمیع کلی مصون میمانند.
PEAP چه میکند؟
- اهمیت هر ارتباط (edge) را محاسبه میکند
- بهجای تجمیع در کل توالی، اهمیت هر edge را در هر موقعیت به صورت مستقل بررسی میکند
نتیجه تشخیص:
- کدام لبه فقط در موقعیت مشخص اهمیت دارد
- کدام لبه فقط در یک span مفهومی فعال میشود
- کدام لبه ارتباط بین دو موقعیت دارد (cross-positional)
مدار نهایی:
- کوچکتر
- دقیقتر
- کمخطاتر
- بسیار نزدیکتر به رفتار واقعی مدل 🎯
🧩 مثال کاربردی: دادهی “Greater-Than”
نمونه ورودی: “The war lasted from the year 1741 to the year 17”
وظیفه مدل: تشخیص کدام سال بزرگتر است.
روشهای قبلی: لبهها یکسان فرض میشدند → مدارهای بزرگ و کمکیفیت
PEAP: استخراج ارتباطات فقط در موقعیتهای خاص → حذف لبههای اشتباه
با تعداد لبههای بسیار کمتر
همان عملکرد یا حتی بهتر
🔄 چالش اصلی: دادههای با طول متغیر
چالش اصلی در تحلیل مدارهای درونی مدلهای زبانی این است که ورودیهای واقعی طول ثابت ندارند و همین موضوع باعث میشود مقایسهٔ مستقیم لبهها بین نمونههای مختلف تقریباً غیرممکن شود. وقتی طول توالی تغییر میکند، تعداد توکنها، موقعیتها و در نتیجه ساختار گراف محاسبات نیز تغییر میکند؛ بنابراین لبهای که در یک ورودی اهمیت دارد، ممکن است در ورودی دیگر اصلاً وجود نداشته باشد یا در جای متفاوتی ظاهر شود. این ناهمگونی ساختاری اجازه نمیدهد که لبهها را از نمونهای به نمونهٔ دیگر همتراز یا مقایسه کنیم، و همین موضوع تحلیل مدارها، شمارش ویژگیها و کشف رفتار مکانیکی مدل را دشوار میکند.
ورودیهای واقعی طول ثابت ندارند → مقایسه لبهها بین نمونهها ممکن نیست.
🏗️ مفهوم Schema
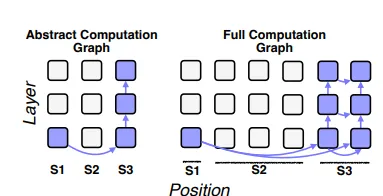
«Schema» بهمعنای تقسیمبندی توالی ورودی به spanهای معنایی است، نه تقسیمبندی بر اساس موقعیتهای عددی. این کار باعث میشود که مدل از سطح توکن فراتر رفته و بر پایهٔ نقشها و ساختارهای معنایی جمله تحلیل شود؛ مثلاً بخشهایی مانند Subject، Year1، Year2 یا Transition بهعنوان واحدهای مفهومی درنظر گرفته میشوند. مزیت اصلی Schema این است که طول ورودی و محل دقیق توکنها دیگر اهمیتی ندارد و مدارها بر اساس نقش معنایی مقایسه میشوند، نه جایگاه فیزیکی در توالی. این موضوع اجازه میدهد مدار نهایی واقعاً رفتار مدل را توضیح دهد و وابسته به طول ثابت یا ساختار ظاهری نباشد:
«The war» → Subject
«lasted from the year» → Context
«1741» → Year1
«to the year» → Transition
«1760» → Year2
فایده:
- طول ورودی مهم نیست
- مقایسه بر اساس نقش معنایی
- مدار واقعاً توضیحدهنده رفتار مدل
🎛️ مراحل کشف مدار در سطح Schema
- محاسبه اهمیت لبهها برای هر مثال
- نگاشت به لبههای abstract طبق schema
- تجمیع اهمیت در سطح schema
- ساخت گراف abstract
- نگاشت مجدد به مدار واقعی در هر مثال
نتیجه مدار نهایی:
- بر اساس نقش معنایی
- سازگار با طولهای متفاوت
- موقعیتمحور
- نزدیکتر به مدل واقعی
🤖 ساخت خودکار Schema با LLM
ساخت دستی Schema فرایندی بسیار زمانبر، حساس و اغلب ذاتاً سلیقهای است؛ بنابراین نویسندگان از یک LLM برای استخراج خودکار Schema استفاده میکنند. این فرایند شامل :
- استخراج الگو از نمونهها
- یافتن نقشهای مشترک
- پیشنهاد schema منسجم
- اعمال و اصلاح خودکار
در آزمایشها سه نسخهٔ متفاوت مقایسه شدهاند: نسخهای که فقط توسط LLM ساخته شده، نسخهای که با کمک Mask هدایت شده (LLM+Mask) و نسخهٔ طراحیشده توسط متخصص انسانی. هدف این است که نشان دهد آیا LLM میتواند بدون دخالت مستقیم انسان به یک ساختار معنایی قابلاعتماد و کاربردی برسد یا خیر.
📊 نقش Saliency Mask
Saliency Mask بهعنوان ابزاری بهکار میرود که به LLM کمک کند توکنها را بر اساس اهمیت واقعیشان دستهبندی کند. این ماسک از Saliency Scoreها استفاده میکند تا نشان دهد کدام توکنها بیشترین تأثیر را در پیشبینی دارند و کدام بخشها باید در Schema جداگانه درنظر گرفته شوند. ترکیب LLM با Mask باعث میشود که خروجیها کمتر وابسته به حدسهای زبانی مدل بوده و بیشتر بر پایهٔ سیگنال واقعی مدل پایه شکل بگیرند. طبق نتایج مقاله، این کار به مدارهایی منجر میشود که کوچکتر، دقیقتر و وفادارتر به رفتار مدل اصلی هستند.
🧪 آزمایشها و ارزیابی رویکرد Position-Aware
مجموعهدادهها شامل موارد زیر هستند:
- 📅 Greater-Than – مقایسهی سالها یا اعداد
- 🔁 Same-Phrase – شناسایی تطابق عبارتها در یک جمله
- 🧩 IOI (Indirect Object Identification) – شناسایی مفعول غیرمستقیم در جملات پیچیده زبانی
هدف از انتخاب این سه داده، پوشش طیفی از وظایف مختلف است:
- 🔢 مقایسه عددی
- 📝 تطبیق متنی
- 🧩 استدلال نحوی و نقشکلمهای
این تنوع باعث میشود رویکرد پیشنهادی در شرایط مختلف سنجیده شود.
📌 ارزیابی اولیه با دادهی Greater-Than
“The war lasted from the year 1722 to the year 17”
یا نمونههایی که سال اول یا دوم عمداً تغییر داده شدهاند.نتایج نشان میدهد که وقتی مدار با روشهای قبلی استخراج میشود:
- 📌 مدار بزرگتر است
- 📌 حاوی لبههای کماهمیت است
- 📌 وفاداری مدل (faithfulness) پایین میآید
اما با رویکرد PEAP:
- ✅ اهمیت لبهها بر اساس موقعیتشان سنجیده میشود
- ✅ مقایسهی اهمیتها مخدوش نمیشود
- ✅ تداخل محاسبات در spanهای مختلف حذف میشود
در Figure 6 مقاله (ذکر تصویری لازم)، تفاوت میان ساختار مدار پیشنهادی و مدارهای کلاسیک نشان داده میشود. مدار PEAP با لبههای بسیار کمتر، عملکرد مدل را تقریباً بینقص بازتولید میکند.
🔥 مدارهای موقعیتمحور با محاسبات کمتر، وفاداری بسیار بیشتری دارند.
🧬 تحلیل دادهی Same-Phrase
“The cat chased the mouse and the cat was hungry.”
در این وظیفه، مدل باید تشخیص دهد که کدام «the cat» باید تکرار شود. موضوع به ظاهر ساده است، اما در عمل مدلها این رفتار را از طریق interactions پیچیده میان attention headها یاد میگیرند.یافتههای مقاله در این بخش:
- 🧠 نقش attention headها کاملاً بستگی به موقعیت دارد
- 🔹 برخی headها فقط زمان وقوع phrase اول فعال میشوند
- 🔹 برخی فقط phrase دوم را دنبال میکنند
- 🔹 برخی headها اصلاً برای نقش تشخیص phrase بهکار نمیروند
با اعمال PEAP، یک نکتهی کلیدی روشن شد:
لبههایی که فقط در یک موقعیت خاص فعال میشوند، در روشهای کلاسیک حذف میشدند؛ اما در PEAP حفظ میشوند و عملکرد مدار بهبود مییابد.
- 🔹 برخی لایهها تنها در span Subject تأثیرگذارند
- 🔹 برخی headها فقط مسئول انتقال نقش Indirect Object هستند
- 🔹 اهمیت لبهها به شدت وابسته به موقعیت است
- 🔹 در بسیاری از موارد، لبههای مهم Cross-Span هستند
- ❗ بدون Schema و موقعیتمحوری، مدار IOI بهدرستی قابل استخراج نیست
با اعمال روش PEAP، مدار نهایی:
- ✅ کوچکتر
- ✅ قابلتفسیرتر
- ✅ از نظر معنایی روشنتر
در Figure 8 مقاله، مدار نهایی IOI پس از اعمال PEAP نمایش داده شده است. این مدار بهصورت واضح نشان میدهد که نقش هر head چگونه و در کدام span تخصیص داده شده است.
🔬 تحلیل دقیق تفاوت روشها (Baseline vs PEAP)
برای مقایسه دقیق، چند معیار علمی استفاده شده است:
🎯 معیارهای ارزیابی PEAP
1️⃣ Faithfulness
میزان شباهت رفتار مدار به رفتار مدل اصلی.
• روشهای قدیمی: پایینتر
• روش PEAP: بسیار بالا
2️⃣ Sparsity
تعداد لبههای حذفشده نسبت به کل محاسبات.
• روشهای قبلی: مدار بزرگ
• روش PEAP: مدار کوچک و مینیمال
3️⃣ Stability
میزان ثبات مدار هنگام تغییر طول ورودی.
• روشهای کلاسیک: بیثبات
• روش PEAP: پایدار و سازگار با ورودیهای متغیر
4️⃣ Semantic Alignment
همترازی مدار با ساختار معنایی جملهها.
• PEAP از طریق schema این همترازی را تضمین میکند
• روشهای دیگر معمولاً این بخش را نادیده میگیرند
🔧 بررسی تفاوت نقش Attention Headها
یکی از جذابترین بخشها، بررسی دقیق تفاوت عملکرد headهاست. با استفاده از PEAP مشخص شد:
🧠 نقش Headها در موقعیتهای مختلف
- Headهای خاصی فقط زمانی فعالاند که دو سال عددی مقایسه میشوند
- برخی headها فقط نقش انتقال tokenهای قبلی را دارند
- برخی headها spanها را به هم متصل میکنند
- Headهایی که به نظر مهم میرسیدند، در واقع در موقعیتهای دیگر بیاثر بودند
این یافتهها نشان میدهد بسیاری از تحلیلهای قبلی که headها را «مهم» یا «غیرمهم» میدانستند، در واقع دچار خطا بودهاند، چون موقعیت را نادیده گرفته بودند.
در نتیجه، PEAP توانست:
- نقش واقعی headها را با دقت بسیار بالا مشخص کند
- لبههای غیرمؤثر را حذف کند
- دقت مدار استخراجشده را افزایش دهد
🔗 مدارهای Cross-Positional
بخشی دیگر از مقاله نشان میدهد که بسیاری از محاسبات مهم مدل، نه در ناحیههای ثابت، بلکه در تعامل بین موقعیتها رخ میدهد. این لبهها cross-positional نامیده میشوند.
مثالها:
- ارتباط span سال ۱ با span سال ۲
- ارتباط phrase نخست با phrase دوم
- ارتباط ضمیر با مرجع آن
روشهای قدیمی، اهمیت این لبهها را «بهطور متوسط» حساب میکردند، بنابراین اگر این ارتباط فقط در برخی موقعیتها مهم بود، در نهایت حذف میشد.
اما در PEAP:
در نتیجه مدار نهایی نهتنها کوچکتر و دقیقتر است، بلکه واقعاً ماهیت محاسبات مدل را بهدرستی منعکس میکند.
🧱 نقش Schema در کاهش نویز
دادههایی که طول متغیر دارند، بهطور طبیعی نویز زیادی ایجاد میکنند. مثلاً:
- تعداد توکنها متفاوت است
- فاصله بین spanها متغیر است
- ساختار جمله پیچیدهتر یا کوتاهتر میشود
در این حالت اگر مدار بر اساس موقعیت عددی ساخته شود، مقایسهها کاملاً اشتباه میشوند.
Schema با تعریف نقشهای معنایی، این چالش را بهطور کامل رفع میکند.
دستاوردهای schema:
- کاهش چشمگیر نویز
- افزایش پایداری مدار
- افزایش همترازی معنایی
- امکان مقایسه میان مثالها
- استخراج مدارهای abstract قابلفهم برای انسان
در Figure 5 مقاله، نحوه نگاشت circuit abstract به example-specific circuit نمایش داده شده است.
🤖 عملکرد LLM در استخراج Schema
پژوهش نشان میدهد که استفاده از LLMها برای ساخت خودکار schema کاملاً کارآمد است.
نکات مهم:
- LLMها میتوانند الگوی عمومی داده را استخراج کنند
- نقشهای معنایی را با دقت بالا تشخیص میدهند
- در بسیاری موارد، schema بهتر از نسخهی طراحیشده توسط انسان است
اما:
- اگر به LLM فقط متن داده شود، ممکن است نقشهای بیاهمیت تولید کند
- استفاده از saliency mask این مشکل را برطرف میکند
- LLM با saliency mask میتواند تشخیص دهد کدام بخش جمله بیشترین تأثیر را دارد
PEAP + Schema روشی انقلابی برای استخراج مدارهای وفادار، کوچک و واقعاً قابلتفسیر از مدلهای زبانی بزرگ است.
🧩 ترکیب Schema و PEAP؛ شکلگیری مدارهای انتزاعی دقیق و قابلتفسیر
1. استخراج مدار موقعیتمحور (PEAP)
2. ساختاردهی نقشهای معنایی با Schema
—منجر به تولید مدارهایی میشود که:
- کوچکتر
- دقیقتر
- قابلتعمیم به ورودیهای متغیر
- و مهمتر از همه قابلتفسیر توسط انسان هستند
🤔 مدار انتزاعی (Abstract Circuit) چیست؟
بهجای اینکه هر ارتباط میان positionهای 1، 2، 3 محاسبه شود، ارتباطهای میان spanها و نقشهای معنایی ثبت میشود؛ مثال:
- ارتباط Year1 → Year2
- ارتباط Subject → Verb
- ارتباط IO → Pronoun
این شکل از مدار نهتنها رفتار مدل را بهتر نمایش میدهد، بلکه برای خواننده انسانی کاملاً قابل فهم است.
در Figure 10 مقاله نمونهای از مدار انتزاعی نشان داده شده که ارتباطهای کلیدی در وظیفه IOI را در یک گراف ساده نمایش میدهد.
🛠️ فرایند ساخت مدار نهایی در سطح داده واقعی
پس از تعیین schema و کشف مدار انتزاعی، مقاله توضیح میدهد که چگونه باید مدار نهایی برای هر مثال خاص استخراج شود.
- نگاشت مدار انتزاعی به مدار واقعی: هر لبه abstract به لبههای واقعی مربوط به spanها در مثال اصلی نگاشت میشود.
- اعمال PEAP بر هر مثال: اهمیت لبهها دوباره اندازهگیری میشود اما فقط در مسیرهایی که توسط مدار انتزاعی تعیین شدهاند.
- حذف لبههای کماهمیت: مدار واقعی در هر مثال کوچکتر میشود و ساختاری واضح پیدا میکند.
- ارزیابی نهایی Faithfulness: در همه آزمایشها، مدار حاصل تقریباً با خروجی مدل اصلی یکسان عمل میکند.
📊 نتایج تجربی کلیدی
مقاله با ارائهی چند جدول و نمودار، جمعبندی تجربهها را ارائه میدهد. برخی نتایج مهم عبارتاند از:
- تعداد لبهها بهطور میانگین ۳۰ تا ۶۰ درصد کمتر است
- اما سطح بازسازی خروجی مدل بهطور چشمگیری بالاتر باقی میماند
در Figure 6 و Figure 9 این کاهش اندازه همراه با افزایش faithfulness نمایش داده شده است.
روشهای baseline معمولاً فرض میکنند که ارتباطات مهم همواره یکساناند. مقاله نشان میدهد که:
- برخی لبهها فقط در یک span مهماند
- برخی لبهها فقط در حالت خاصی فعالاند
- برخی headها فقط هنگام تغییر موقعیت مرجع عمل میکنند
با ترکیب نقشها در spanهای معنایی و تفکیک موقعیتی، این خطاها برطرف میشود.
این بخش مهمترین دستاورد مقاله است.
مدارهایی که بر اساس schema ساخته شدهاند:
- ساختار منطقی دارند
- توزیع معنایی واضحی دارند
- تعامل میان spanها را بهروشنی نشان میدهند
- برخلاف مدارهای خام baseline، واقعاً مکانیسم مدل را بیان میکنند
طراحی دستی schema برای datasetهایی مانند IOI یا Same-Phrase ممکن است روزها زمان ببرد.
اما LLM میتواند:
- ساختار داده را تشخیص دهد
- spanها را تفکیک کند
- نقشهای معنایی را استخراج کند
- و در نهایت schema پیشنهادی را ارائه دهد
در آزمایشها، روش ترکیبی LLM+Mask بهترین عملکرد را داشته است.
⚡ تحلیل عمیق نقش Spanها در مدار IOI
در بخش پایانی مقاله، مجموعهای از یافتههای میکروسکوپی در وظیفه IOI بررسی شده است. این بخش نشان میدهد که:
🔹 headهای مرتبط با انتقال اسمها بهطور خاص در spanهای قبل از ضمیر فعال هستند
🔹 برخی لبهها نقش جداسازی نقشهای نحوی را دارند و اگر حذف شوند، مدار بهکلی عملکرد خود را از دست میدهد.
این یافتهها نشان میدهد که مدل واقعاً از یک مکانیسم درونی پایدار برای رفع ابهام ضمیر استفاده میکند و مدار بهدستآمده این مکانیسم را کاملاً بازتاب میدهد.
🎯 اهمیت این پژوهش برای آیندهی تفسیرپذیری مدلهای زبانی
در جمعبندی مقاله توضیح داده میشود که چرا این روش نقطه عطفی در حوزه تفسیرپذیری مکانیکی محسوب میشود:
- ✔️ ۱. اولین روش استاندارد برای تحلیل لبهها بهصورت موقعیتمحور
تمام روشهای قبلی موقعیت را نادیده میگرفتند. PEAP این شکست را بهطور کامل برطرف کرده است. - ✔️ ۲. پشتیبانی از دادههای واقعی با طول متغیر
نیاز به ورودیهای همطول از بین میرود. این موضوع امکان تحلیل مجموعهدادههای واقعی را فراهم میکند. - ✔️ ۳. ترکیب Schema با تفسیر مکانیکی
این یک گام مهم است، چون مدارهای abstract:
• سادهتر
• قابلنمایش
• و مناسب برای مستندسازی رفتار مدلها هستند. - ✔️ ۴. خودکارسازی با LLM
یکی از بزرگترین موانع تفسیر مدلها، هزینه زمانی و انسانی آن است. این روش بسیاری از مراحل را خودکار میکند و بنابراین:🔥 تفسیر مدلهای بزرگ اکنون قابل اجرا و مقیاسپذیر شده است.
🧭 جمعبندی نهایی مقاله
مدارهایی که این دو عنصر را نادیده میگیرند، پر از نویز، غیرقابلاعتماد و در بسیاری مواقع گمراهکننده هستند.
اما روش Position-Aware Edge Attribution Patching (PEAP):
• رفتار مدل را بهطور واقعی نمایش میدهد
• لبههای مهم را دقیقاً در موقعیتهای درست شناسایی میکند
• مدارهای کوچک اما قدرتمند تولید میکند
• و با کمک schema، امکان تحلیل دادههای پیچیده را فراهم میکند
این پژوهش گامی مهم در جهت «فهم سازوکار درونی مدلهای زبانی» است و نشان میدهد مسیر آیندهی تفسیرپذیری باید:
• موقعیتمحور
• نقشمحور
• و متکی بر مدارهای انتزاعی باشد.
مقاله قبلی :انقلاب هوش مصنوعی کوانتومی در درک زبان انسان👉



